Correlation ID in ASP.NET Core: Custom Middleware vs HttpContext.TraceIdentifier vs W3C Trace Context — Enterprise Decision Guide
When a request fails somewhere in a distributed system, the first question is: which log entries belong to this request, and which service did it touch? Correlation IDs are how you answer that question reliably. In ASP.NET Core, there are at least three distinct ways to approach correlation ID management - each with different trade-offs that matter significantly in enterprise contexts.
The decision is not as simple as "just add a header." The full implementation - with production-ready propagation across HttpClient calls, background jobs, message queues, and Serilog enrichment with OpenTelemetry integration - is available on Patreon, including the source code used at the enterprise level to trace requests across microservices reliably.
Understanding how correlation IDs fit into your broader observability strategy is exactly what Chapter 14 of the ASP.NET Core Web API: Zero to Production course covers - including structured logging, OpenTelemetry, and health checks, all wired together in a single production API codebase.

What Is a Correlation ID and Why Does It Matter?
A correlation ID is a unique identifier attached to an incoming request and propagated across every service, log entry, and background operation that request touches. When something goes wrong, you can filter your logs by a single ID and reconstruct the full request journey - across multiple APIs, message queues, and asynchronous jobs.
Without a correlation ID strategy, debugging distributed failures requires correlating timestamps, guessing which log entries are related, and hoping that nothing ran in parallel at the same time. With a solid strategy, you query one field and get the complete picture.
The challenge is that ASP.NET Core offers multiple mechanisms that seem to solve this problem - and teams frequently pick the wrong one for their context, or mix them in ways that create ambiguity rather than clarity.
The Three Approaches: An Overview
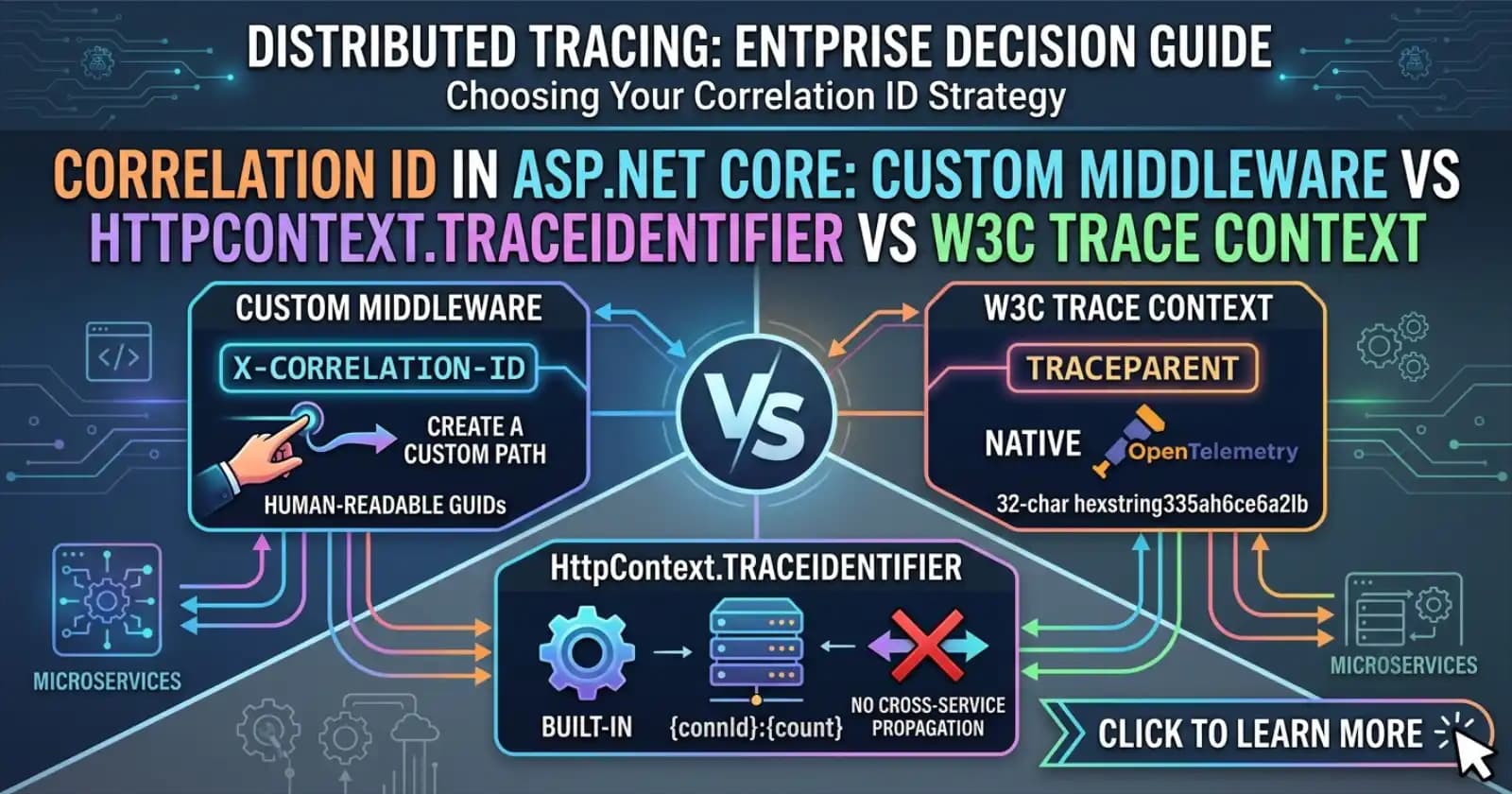
Custom Middleware with X-Correlation-ID Header
The most explicit approach: write middleware that reads an inbound X-Correlation-ID header (or generates a new GUID if none is present), stores it in HttpContext.Items, adds it to ILogger scope, and forwards it on all outbound HttpClient calls via a DelegatingHandler.
This gives you complete control over naming, storage, propagation strategy, and header format. It integrates cleanly with Serilog's LogContext.PushProperty so every log line within that request automatically carries the correlation ID.
The trade-off: it is entirely your responsibility. There is no standard, no automatic tooling support, and you must instrument every outbound call manually if you want propagation to work.
HttpContext.TraceIdentifier
HttpContext.TraceIdentifier is a built-in property that ASP.NET Core assigns to every request. It is a unique string identifier - in Kestrel it is formatted as {connectionId}:{requestCount}, which makes it deterministic but not human-friendly.
The appeal is obvious: it is always there, requires no middleware, and is already included in ASP.NET Core's default request logging (UseRouting, UseSerilogRequestLogging). You can read it anywhere you have access to IHttpContextAccessor.
The limitation: TraceIdentifier is an internal implementation detail. It is scoped to a single application instance. If you want to track a request across services, you cannot use TraceIdentifier as the propagation ID because it is never forwarded to downstream services by the framework. It is a local ID, not a distributed one.
W3C Trace Context (traceparent / tracestate)
W3C Trace Context is an IETF standard (RFC specification) that defines two headers: traceparent (carrying version, trace ID, parent span ID, and flags) and tracestate (vendor-specific metadata). ASP.NET Core fully supports this standard through System.Diagnostics.Activity and the ActivitySource API.
When OpenTelemetry is enabled, Activity.Current is automatically populated with W3C-compatible IDs. The TraceId on an Activity is a 128-bit identifier that propagates across service boundaries when downstream HttpClient calls are instrumented. Any OpenTelemetry-compatible backend - Jaeger, Zipkin, Grafana Tempo, Azure Monitor - understands this format natively.
The trade-off: the W3C approach is powerful and standards-compliant, but it adds complexity. You need OpenTelemetry instrumentation wired up, and the TraceId is verbose (a 32-character hex string) compared to a GUID. For simple scenarios - a single-service API or a small team - this can be more infrastructure than the problem warrants.
When to Use Which Approach
Use Custom Middleware (X-Correlation-ID) When:
Your system is not using OpenTelemetry and you do not plan to introduce it soon
You need a simple, human-readable ID in logs and error responses (e.g., to share with customers for support tickets)
You want clients to be able to pass a correlation ID from the frontend (mobile apps, browser clients) and trace it end-to-end
Your team is small and the infrastructure overhead of W3C trace context is not justified yet
You need the ID to survive message queue boundaries (RabbitMQ messages, Azure Service Bus) where HTTP headers do not naturally propagate
This is the right starting point for most teams building their first distributed system. It is simple, explicit, and easy to reason about.
Use HttpContext.TraceIdentifier When:
You need a quick, no-setup way to correlate logs within a single service
You are not building a distributed system and the request never leaves one application
You want something in logs immediately without writing middleware
You are adding basic observability to a legacy application and cannot introduce new middleware yet
Never use TraceIdentifier as your correlation ID if the request touches more than one service. It will not propagate, and you will end up with per-service IDs that do not connect.
Use W3C Trace Context When:
You are running OpenTelemetry (or plan to)
Your observability tooling supports distributed tracing natively (Azure Application Insights, Grafana Tempo, Jaeger, Honeycomb)
You have multiple services that all speak the same tracing language
You care about span-level granularity, not just request-level correlation
You are building a new system and can establish the right foundation from the start
W3C Trace Context is the right long-term choice for any team that is serious about distributed observability. It is the standard everything converges on.
Can You Use Both?
Yes - and in practice, most mature enterprise systems do. The pattern is:
Use W3C Trace Context (
Activity.Current.TraceId) as the primary distributed trace ID, handled by OpenTelemetryUse a custom
X-Correlation-IDheader as an application-level correlation ID that clients can pass and that survives non-HTTP boundaries (queues, cron jobs, emails)Enrich structured logs with both - the W3C trace ID for APM tooling correlation, and the application correlation ID for support ticket lookups
The key insight is that these two IDs serve different audiences: the trace ID serves your observability platform, and the application correlation ID serves your support team and your customers.
The W3C TraceId vs X-Correlation-ID Decision Matrix
| Criterion | Custom X-Correlation-ID | HttpContext.TraceIdentifier | W3C Trace Context |
|---|---|---|---|
| Cross-service propagation | ✅ Manual (DelegatingHandler) | ❌ Never propagates | ✅ Automatic (OTel) |
| Client-supplied ID support | ✅ Yes | ❌ No | ⚠️ Via traceparent header |
| Queue/job propagation | ✅ Manual | ❌ No | ⚠️ Manual span propagation |
| Human-readable | ✅ GUID format | ⚠️ conn:count format | ❌ 32-char hex |
| Setup cost | Low | Zero | Medium-high |
| APM tool compatibility | ❌ None built-in | ❌ None built-in | ✅ Native |
| Span-level granularity | ❌ No | ❌ No | ✅ Yes |
Anti-Patterns to Avoid
Relying on TraceIdentifier for distributed tracing. This is the most common mistake. Teams log TraceIdentifier everywhere, then realise it changes per service and is completely useless for cross-service correlation.
Using a shared static correlation ID store. Some teams store the correlation ID in a static variable or a singleton instead of scoped to the request. In async code, this causes correlation IDs from concurrent requests to bleed into each other. Always scope correlation IDs to the request via HttpContext.Items or AsyncLocal<T>.
Not propagating on outbound calls. Generating a correlation ID on the inbound request but forgetting to add it to outbound HttpClient calls defeats the purpose entirely. Use a DelegatingHandler registered at the factory level so propagation is automatic and cannot be forgotten.
Mixing two different header names. Using X-Correlation-ID on some services and X-Request-ID on others means logs across services use different fields. Pick one header name and enforce it across the fleet as a standard.
Generating a new ID on every hop. The ID should only be generated if none arrives with the request. If the client or an upstream service sends a correlation ID, preserve and forward it - do not replace it. This is what allows end-to-end tracing from the client's first request.
What a Production Correlation ID Strategy Looks Like
A mature enterprise correlation ID strategy typically combines:
Inbound middleware - reads
X-Correlation-ID(or generates a new GUID), stores it inHttpContext.Items, and sets it inILoggerscopeOutbound
DelegatingHandler- reads the correlation ID fromIHttpContextAccessorand adds it to every outbound request header automaticallySerilog enrichment -
LogContext.PushProperty("CorrelationId", ...)so every log line in the request carries the field without manual effortOpenTelemetry
ActivitySourcebaggage - for services that use OTel, the correlation ID is added as activity baggage so it flows through the trace graphBackground job propagation - correlation IDs are embedded in message payloads (not just headers) so they survive queue round-trips and deferred execution
This level of depth - including edge cases like Hangfire jobs, Azure Service Bus handlers, and multi-tenant scenarios - is what separates a demo implementation from a production-ready one.
💻 Full source code for the correlation ID middleware - clone it, run it, and adapt it: github.com/codingdroplets/dotnet-request-correlation-middleware
Should You Use a NuGet Package?
There are established NuGet packages for correlation ID management in ASP.NET Core - stevejgordon/CorrelationId and skwasjer/Correlate being the most referenced. These are solid libraries and reasonable choices if you want the basics handled quickly.
The case against a package: correlation ID propagation is not complex to build, and owning the implementation means you understand exactly what is in scope. When you need to extend it - adding to Hangfire jobs, propagating through custom event buses, or integrating with a proprietary APM - a bespoke implementation is far easier to adapt. The package abstraction can become a constraint at the edges.
The case for a package: it handles the edge cases you have not thought of yet. For teams without a dedicated platform engineer, a well-maintained package is a pragmatic choice.
Neither answer is wrong. The trade-off is ownership vs convenience, and both are valid.
FAQ
What is the difference between a correlation ID and a trace ID in ASP.NET Core?
A correlation ID is an application-level identifier - typically a GUID - that you generate and propagate explicitly, often via a custom X-Correlation-ID header. A trace ID (in the W3C sense) is a 128-bit identifier managed by the distributed tracing system (OpenTelemetry, Activity API). They serve overlapping but distinct purposes: the trace ID links spans for APM tooling; the correlation ID links log entries and is human-accessible for support workflows. Enterprise systems often carry both.
Should I use X-Correlation-ID or X-Request-ID as my header name?
Either works at the HTTP level, but standardise on one across your entire fleet. X-Correlation-ID is more widely used in .NET ecosystems and library documentation. X-Request-ID is common in Ruby/Rails and some gateway tools (NGINX, Envoy). If you control all services end-to-end, pick X-Correlation-ID and be consistent. If you integrate with third-party gateways or clients, check what they expect.
Does HttpContext.TraceIdentifier work for distributed tracing?
No. HttpContext.TraceIdentifier is scoped to a single application instance and is never forwarded to downstream services by ASP.NET Core. It is useful for correlating log entries within a single service, but cannot be used to trace a request across services. Use it only for single-service scenarios or as a supplementary field.
How do I propagate a correlation ID through Hangfire or Azure Service Bus in ASP.NET Core?
HTTP headers do not survive the queue boundary. The standard approach is to embed the correlation ID in the message payload or job parameter - as a top-level field, not in the message body. When the consumer processes the message, it reads the correlation ID from the payload and initialises it into the AsyncLocal<T> context or ILogger scope before executing any business logic.
Is W3C Trace Context the right choice for a single ASP.NET Core API with no downstream services?
Probably not. W3C Trace Context is designed for distributed systems. For a single-service API, the overhead of configuring OpenTelemetry exporters, managing Activity spans, and reasoning about trace IDs adds complexity without proportional benefit. For a single service, HttpContext.TraceIdentifier enriched into Serilog logs is sufficient. Add W3C Trace Context when you have a second service to connect to.
How do I add the correlation ID to every Serilog log entry automatically?
Use LogContext.PushProperty("CorrelationId", correlationId) inside your correlation ID middleware, within a using scope that covers the rest of the request pipeline. This enriches every ILogger.Log* call within that scope with the CorrelationId property, so you never have to pass it manually to individual log statements.
Can a client send their own correlation ID and have it propagated?
Yes, and this is often desirable in B2B APIs. Your middleware should check for an inbound X-Correlation-ID header and use that value if present (and validate it as a reasonable length/format), only generating a new ID if none is provided. This allows upstream services or API consumers to set the correlation ID at the point of origin and trace it all the way through your system.
About the Author
Celin Daniel is Co-founder of Coding Droplets with 13+ years of hands-on experience building, shipping, and operating .NET and ASP.NET Core systems in production. The guidance here comes from real projects and production incidents, not theory.
- Website: codingdroplets.com
- GitHub: github.com/codingdroplets
- YouTube: youtube.com/@CodingDroplets