

HTTP Error 500.30 – ASP.NET Core App Failed to Start: Root Causes and Fixes

Search for a command to run...
No comments yet. Be the first to comment.
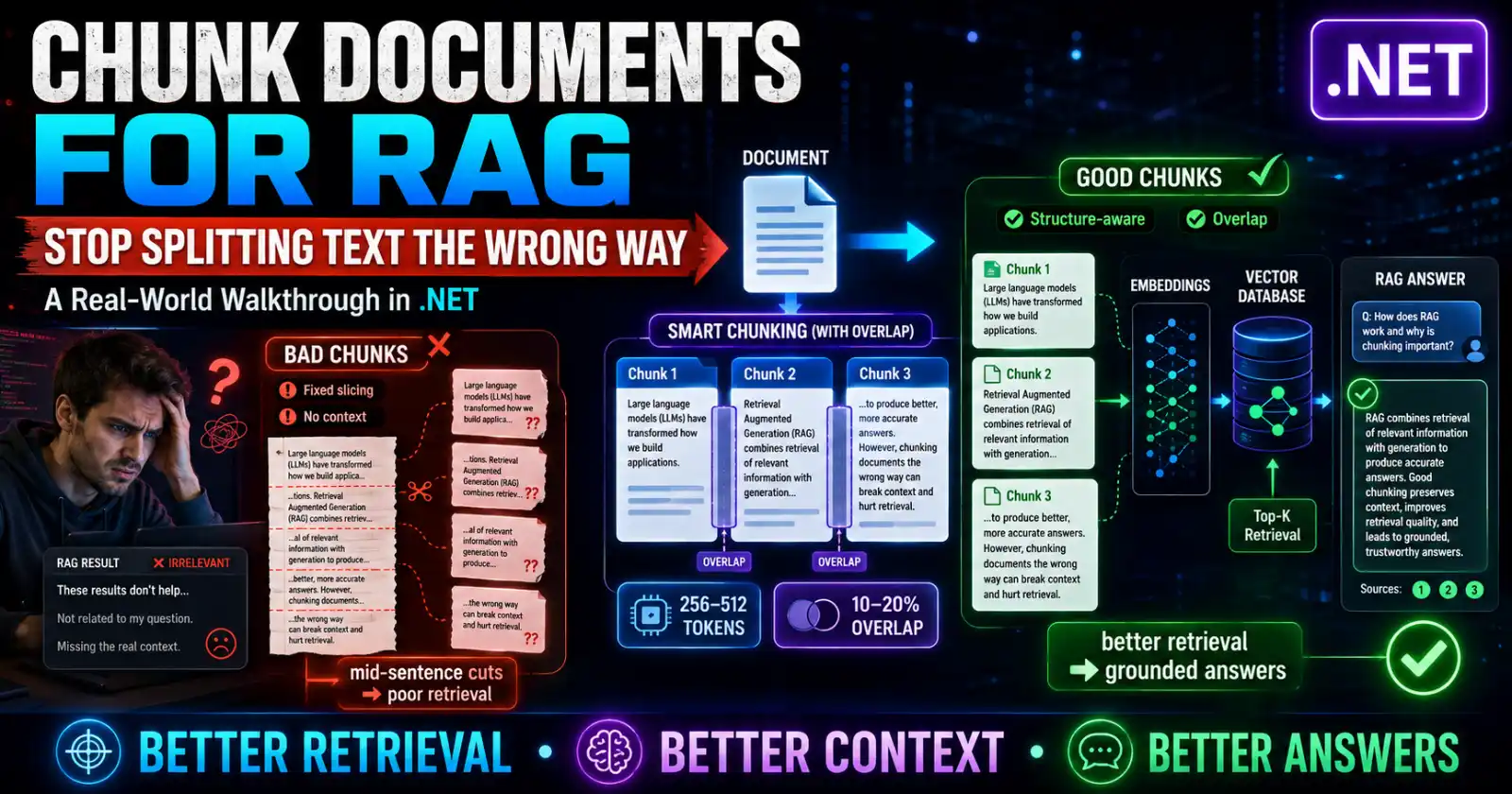
Retrieval-Augmented Generation lives or dies on one unglamorous step, and it is not the model or the vector database. It is chunking. When you get chunking documents for RAG in .NET wrong, the model r
Most teams reach for caching the moment an API gets slow, wire up Redis or output caching, and move on. But there is an older, lighter mechanism built into HTTP itself that solves two problems at once

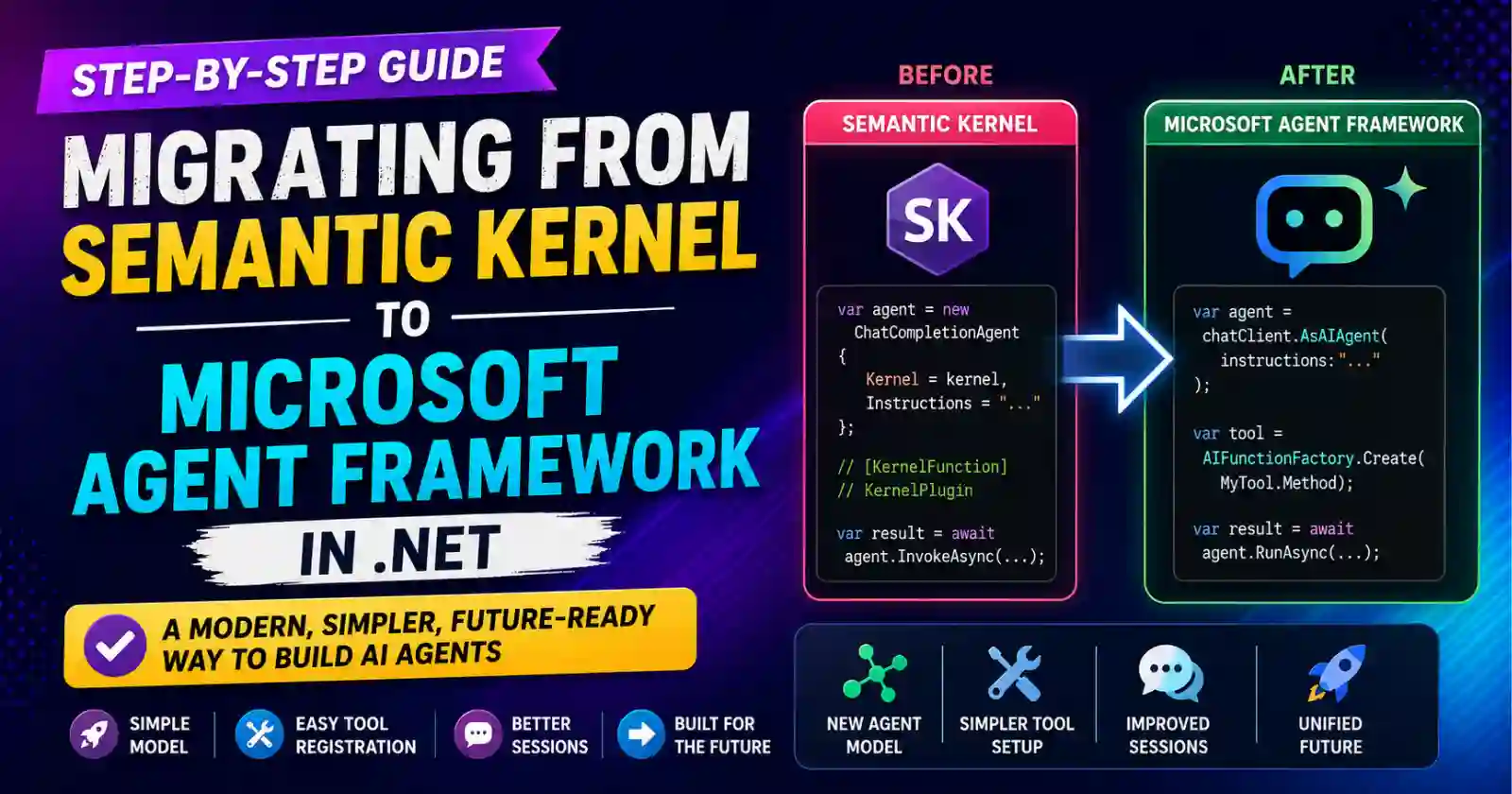
If you shipped an AI agent in .NET over the last two years, there is a good chance it runs on Semantic Kernel. That was the right call at the time. But with Microsoft Agent Framework reaching GA in Ap
The first time an AI feature I shipped went down in production, nothing in my code had changed. The model provider had a bad afternoon: a wave of 429 Too Many Requests, then a stretch of 503s, and eve

If you have tried to add OpenTelemetry.Extensions.Logging to a .NET project, you already know how this ends. The restore fails, NuGet tells you the package cannot be found, and you start second-guessi

Coding Droplets
297 posts
Coding Droplets is your go-to resource for .NET and ASP.NET Core development. Whether you're just starting out or building production systems, you'll find practical guides, real-world patterns, and clear explanations that actually make sense.
From beginner-friendly tutorials to advanced architecture decisions. We publish fresh .NET content every day to help you grow at every stage of your career.
HTTP Error 500.30 is one of the most disorienting errors a .NET team can face in production. The deployment succeeded, the pipeline is green, and then the first request returns a blank error page with a message that tells you almost nothing about what actually went wrong. The fix is rarely hard — but finding the root cause is where most teams lose time. Understanding the structured logging patterns that expose startup failures quickly is exactly what Chapter 14 of the Zero to Production course covers — with a complete production codebase showing how Serilog, OpenTelemetry, and health checks work together to surface problems before users notice.

The complete diagnostic runbook — including the environment-specific configuration patterns and the startup exception handler that keeps production logs readable — is available on Patreon, with annotated source code you can adapt directly to your own deployment pipeline.
When IIS or Azure App Service returns HTTP Error 500.30, it means the ASP.NET Core process started — the OS launched the dotnet executable — but the application threw an unhandled exception before it could reach the point of handling any HTTP requests. The process exited immediately.
This is distinct from a 500 error during request handling. A 500.30 is a process-level failure. The application never reached its request pipeline. From IIS's perspective, the worker process came up and then went down before it could serve anything.
The full error code family looks like this:
500.30 — In-process startup failure (most common)
500.31 — ANCM failed to find native dependencies (e.g., missing ASP.NET Core runtime)
500.32 — Incompatible bitness
500.33 — Failed to load ASP.NET Core module
500.35 — Single-file app launch failure (for self-contained deployments)
Most teams encounter 500.30 and spend time investigating hosting issues when the real cause is in their own application code. This article focuses on 500.30 specifically — the in-process startup failure that you own and can fix.
The core problem is that IIS and Azure App Service suppress the exception details from the browser response by default. This is correct security behaviour — you do not want stack traces surfaced to end users. But in practice, when a team deploys to production for the first time or after a significant configuration change, the suppression means the error page is nearly useless.
Compounding this: many teams configure exception handling middleware inside UseExceptionHandler() or via IExceptionHandler, but these only activate if the application has successfully built and started its HTTP pipeline. If the crash happens in Program.cs before app.Run() is called, none of that middleware ever executes.
The application's own error handling does not help you here. You need the runtime and the host to capture the startup failure, and you need a log destination that is reachable before the app's own logging infrastructure initialises.
The most reliable first step when running behind IIS is to enable stdout logging in web.config:
<aspNetCore processPath="dotnet"
arguments=".\YourApp.dll"
stdoutLogEnabled="true"
stdoutLogFile=".\logs\stdout"
hostingModel="inprocess" />
Set stdoutLogEnabled="true" and point stdoutLogFile to a writable directory. The runtime will write the raw exception and stack trace to that file before the process exits. Make sure the logs\ folder exists — IIS will not create it.
⚠️ Disable stdout logging immediately after diagnosing. Leaving it enabled long-term creates large, unmanaged log files and a minor performance overhead.
ASPNETCORE_DETAILEDERRORS in DevelopmentOn Azure App Service, set the application setting ASPNETCORE_DETAILEDERRORS to true in a staging slot. This makes the runtime surface the exception in the browser response. Never set this on a production slot.
On IIS hosts, the Event Log under Windows Logs → Application will contain the .NET runtime's own error event with the exception type and message. This is often faster than waiting for stdout logs to populate.
For apps using the top-level statement model, wrapping app.Run() in a try/catch and logging the exception directly gives you the raw startup error without relying on host-level logging:
try
{
var app = builder.Build();
// middleware registration
app.Run();
}
catch (Exception ex) when (ex is not HostAbortedException)
{
Log.Fatal(ex, "Application failed to start");
throw;
}
finally
{
Log.CloseAndFlush();
}
The HostAbortedException exclusion prevents swallowing intentional host shutdowns from tools like dotnet ef. This pattern is idiomatic with Serilog's bootstrap logger and ensures your structured log sink captures the failure even before the full logging pipeline is configured.
The single most frequent cause of 500.30 in production is a configuration value that exists locally but is absent from the production environment. ASP.NET Core's configuration system is fail-fast by design: if you call builder.Configuration.GetSection("MySection").Get<MyOptions>()! and MySection does not exist, the ! dereferences a null and throws a NullReferenceException at startup.
More commonly, teams use the Options pattern with ValidateOnStart():
builder.Services.AddOptions<DatabaseOptions>()
.BindConfiguration("Database")
.ValidateDataAnnotations()
.ValidateOnStart();
ValidateOnStart() is exactly what you want — it surfaces missing configuration at startup rather than silently failing on first use. But it does mean a missing connection string in production will cause a 500.30. The fix is not to remove ValidateOnStart() — it is to make sure the configuration value is present in the deployment environment before the app starts.
What to check:
Connection strings (ConnectionStrings:*)
API keys and secrets
Feature flag provider URIs
External service endpoints
Use environment-specific appsettings.{Environment}.json files for defaults, and override secrets using environment variables or your secrets manager at deploy time. Never rely on appsettings.json alone for production values.
When builder.Build() is called, ASP.NET Core validates the service container. If a service is registered with a dependency that cannot be resolved — or a lifetime mismatch is detected — the container throws an InvalidOperationException before the application starts.
Common patterns that cause this:
Injecting a scoped service into a singleton at registration time (lifetime mismatch)
Referencing a service that was never registered
Using AddHttpClient<T>() but forgetting to register the typed client's interface
An IHostedService implementation that requires a scoped dependency without IServiceScopeFactory
The error message from the DI container is usually very clear about which service failed to resolve. The problem is that teams often first see it as a 500.30 with no visible message. Once stdout logging is enabled, the InvalidOperationException from the container will be the first thing in the log.
Runtime DI validation (enabled by default in Development) catches most of these locally. Teams run into 500.30 in production when they deploy a change that works locally but references a service that is only registered in certain environments, or when a new library registers services conditionally based on configuration.
Any startup code that calls into EF Core — MigrateAsync(), EnsureCreatedAsync(), database seeding — will throw at startup if the database connection fails. This is one of the most common causes of 500.30 in containerised and cloud deployments, particularly when the application container starts before the database is ready.
The failure pattern:
Container orchestrator brings up the API pod
Database pod is still initialising
API's startup code calls MigrateAsync()
SqlException or TimeoutException propagates out of the startup extension method
500.30
The fix is never to call MigrateAsync() unconditionally on every startup in a production environment. For high-availability deployments, migrations should be applied as a separate step in the deployment pipeline, not at application startup. The application should start independently of migration state.
If you need startup-time database validation (as opposed to migration), use a health check dependency with a readiness probe instead. The health check system separates "can I reach the database?" from "can I serve traffic?" — meaning the container can restart and retry without propagating a startup crash.
If the target machine or container does not have the correct .NET runtime version installed, the process will fail before any managed code runs. This produces a 500.31 or 500.32 rather than a 500.30, but it is worth including here because teams often conflate the codes.
Framework-dependent deployments require the exact .NET runtime version to be pre-installed on the host. If you publish targeting .NET 10 but the host has .NET 8, the process cannot start.
Self-contained deployments bundle the runtime and do not have this problem — but they are larger and must match the target OS architecture. A self-contained Linux x64 build will not run on Linux ARM64.
The definitive fix for version mismatch is to use self-contained, single-file deployments for containerised production workloads, or to pin the runtime version in your container base image and keep it aligned with your SDK version in the build pipeline.
Applications that load secrets from Azure Key Vault, AWS Secrets Manager, or similar providers at startup will crash with 500.30 if the secrets provider is unreachable or if the managed identity lacks the required permissions.
This is a particularly tricky category because:
It works correctly when the developer runs locally with their own Azure credentials
It works correctly in staging if the managed identity has been granted access
It fails in production after a re-deploy if the managed identity was reassigned (e.g., app service plan change, resource group move)
Symptoms: The application worked before and now returns 500.30 after infrastructure changes, with no code changes deployed.
What to check:
Managed identity is assigned to the resource (App Service, Container App, AKS pod identity)
Key Vault access policy or RBAC role assignment includes Key Vault Secrets User for the correct identity
The Key Vault URI in configuration matches the actual vault name and region
No network ACL or VNet restriction is blocking the app's outbound connection to Key Vault
The safest pattern is to add a try/catch around the Key Vault AddAzureKeyVault call with a fallback that logs a fatal error and exits gracefully, rather than propagating an unhandled exception through the host.
The least obvious category: environment variables like DOTNET_STARTUP_HOOKS or ASPNETCORE_HOSTINGSTARTUPASSEMBLIES can inject assemblies into the startup process. If one of those assemblies is missing from the deployment package, or if it was set by a development tool and not cleared for production, the runtime will fail to load it and exit with 500.30.
This is common in two scenarios:
Visual Studio tooling sets DOTNET_STARTUP_HOOKS to a path on the developer's machine, and this variable leaks into the build pipeline or deployment configuration
A third-party APM or profiling agent (Datadog, Dynatrace, Azure Monitor) sets startup hooks via environment variables, and the deployment is missing the agent's native libraries
What to check: Review all environment variables set on the production deployment target. Any DOTNET_STARTUP_HOOKS, ASPNETCORE_HOSTINGSTARTUPASSEMBLIES, or DOTNET_ADDITIONAL_DEPS values that reference paths on a developer's machine will cause startup failures in production.
Preventing 500.30 errors is mostly a configuration management and deployment pipeline discipline problem, not an application code problem. These practices address the most common causes:
Validate configuration before building the host. Use the Options pattern with ValidateDataAnnotations() and ValidateOnStart() for all required configuration sections. This gives you a clean, informative startup error rather than a null reference exception buried in a service constructor.
Run migrations out-of-band. Apply database migrations as a pipeline step before the application starts, not inside Program.cs. The application startup should only perform fast, stateless operations. If the app can start without the database being in a specific migration state, it should.
Use health checks instead of startup-time connectivity tests. Liveness and readiness probes let orchestrators (Kubernetes, Azure Container Apps) manage restart behaviour without crashing the process. A failed readiness check keeps traffic away from the pod; a crashed process causes a restart loop.
Test in a clean environment before production. The most common cause of "it worked on my machine" 500.30 errors is a missing environment variable. Run your application in a clean environment (a Docker container with only production environment variables set) before deploying.
Bootstrap Serilog before the host builds. A bootstrap logger configured before WebApplication.CreateBuilder() will capture exceptions thrown during host construction, including DI validation failures and configuration errors. This is the most reliable way to get a structured log entry for a 500.30.
Pin your base image version. In container deployments, using mcr.microsoft.com/dotnet/aspnet:latest as your runtime base image can lead to version mismatches when the latest tag moves. Pin to a specific version tag and update it deliberately as part of your upgrade process.
Kubernetes deployments add a layer of complexity because pod restarts are automatic and fast. A 500.30 in Kubernetes will cause the pod to restart continuously (CrashLoopBackOff), and the original exception will only be visible in the pod logs from the first failed start — which may scroll off if the restart interval is short.
Key practices for Kubernetes environments:
Configure a startup probe with a generous failure threshold for apps that do legitimate startup work (migration checks, cache warmup). This prevents premature restarts during slow but valid initialisation.
Separate liveness from readiness. A liveness probe that fires too early will kill a healthy pod that is still initialising. Use /health/live for liveness (process is running) and /health/ready for readiness (can handle traffic). Never use the same endpoint for both.
Use imagePullPolicy: Always in development and staging namespaces. A pod that starts from a stale cached image will silently use old code, which can appear as a 500.30 if the old code is incompatible with the current database schema.
When you hit 500.30 in production, this is the fastest path to the root cause:
Enable stdout logging in web.config (or check Azure App Service logs immediately via Kudu or Log Stream)
Check the Windows Event Log — Application section — for the raw exception
Look at the last deployment change — what configuration, environment variable, or infrastructure changed?
If it was working before and stopped, the cause is almost certainly a secrets provider permission change or a missing environment variable
If it failed on first deploy, check DI registration validity and configuration section completeness
The actual fix is almost always straightforward once you have the exception message. The hard part is getting to that message — which is why the bootstrap logger pattern and stdout logging discipline matter so much in production.
☕ Prefer a one-time tip? Buy us a coffee — every bit helps keep the content coming!
HTTP Error 500.30 is an in-process startup failure. It means the ASP.NET Core process was launched by IIS or Azure App Service but threw an unhandled exception before building or starting the HTTP request pipeline. The process exits before serving any requests.
Enable stdout logging in web.config by setting stdoutLogEnabled="true" and pointing stdoutLogFile to a writable directory. The runtime will write the full exception and stack trace there. On Azure App Service, use the Log Stream in the Azure Portal or set ASPNETCORE_DETAILEDERRORS=true in a non-production slot.
The most common reason is a missing environment variable or configuration section. Your local machine has connection strings, API keys, or Azure credentials in user secrets or environment variables that have not been set in the production deployment environment. Use ValidateOnStart() with the Options pattern to surface these mismatches as clear error messages rather than null reference exceptions.
Yes. When builder.Build() is called, ASP.NET Core validates the service container. A service that cannot be resolved — due to a missing registration, a lifetime mismatch, or a misconfigured typed HttpClient — will throw an InvalidOperationException at build time, which manifests as a 500.30.
Yes, and it is especially common when the application container starts before the database is ready, causing EF Core migration code in Program.cs to throw a SqlException. The fix is to move migrations out of application startup and into the deployment pipeline, and to use health check readiness probes to keep traffic away from the pod until it is genuinely ready.
500.30 is an application-level startup failure — your code threw an exception. 500.31 indicates the .NET runtime host could not find its native dependencies (missing ASP.NET Core Hosting Bundle). 500.32 is a bitness mismatch — for example, a 64-bit app running in a 32-bit application pool.
ValidateOnStart() in production?Yes. ValidateOnStart() is one of the most useful production safety mechanisms in ASP.NET Core. It ensures that required configuration is present and valid before your app accepts any traffic. A 500.30 caused by ValidateOnStart() is better than a 500 error on the first real request because it fails fast, is easy to diagnose, and surfaces in your deployment pipeline where it can be caught before traffic hits the app.