Long-Running Operations in ASP.NET Core APIs: Enterprise Decision Guide
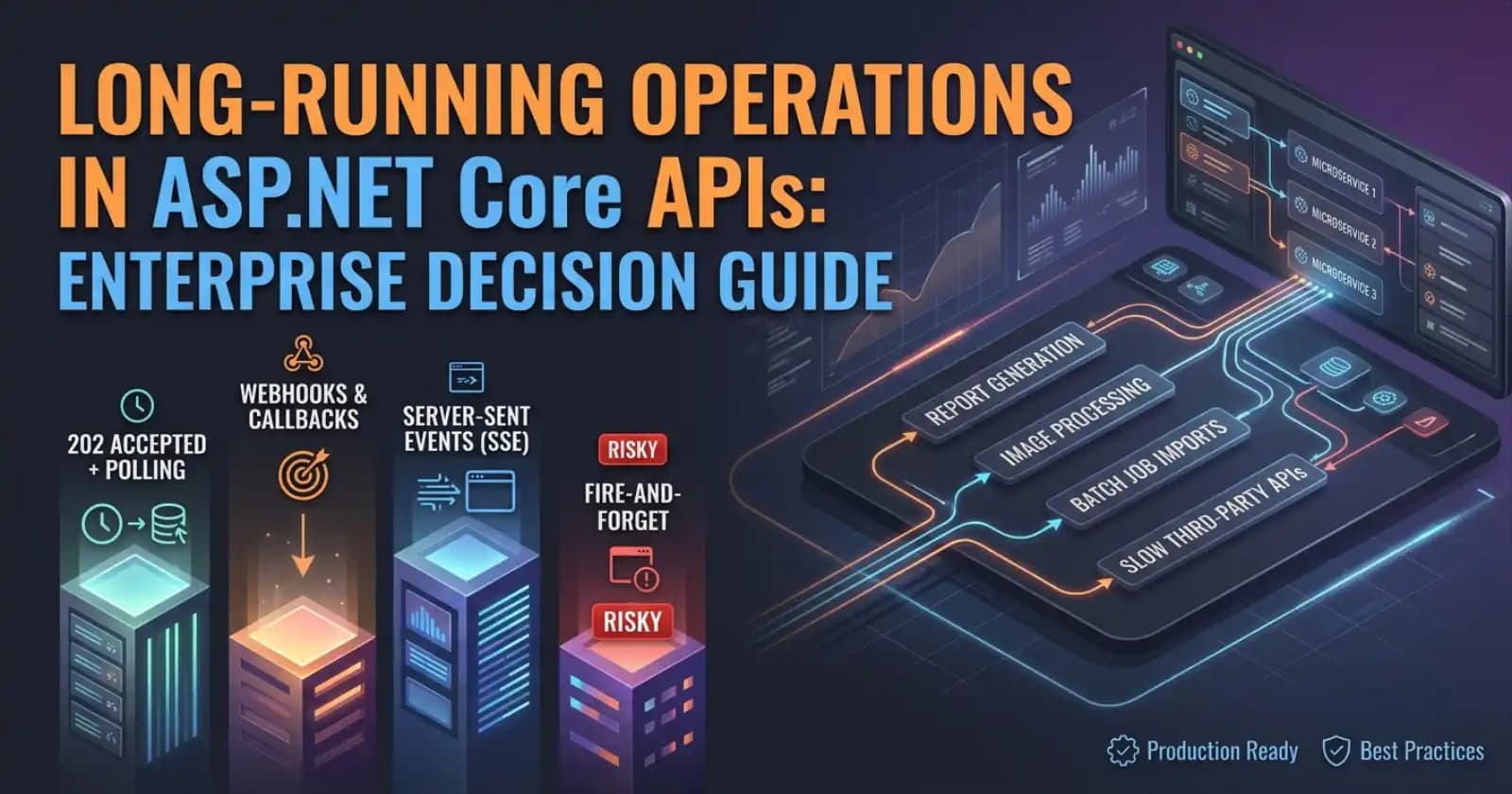
Every enterprise API team eventually builds an endpoint that does too much — a report that takes 30 seconds, an image processing pipeline, a batch job triggered by an external system. Synchronous HTTP is the wrong tool for these operations, but the right alternative is not obvious. In ASP.NET Core, there are four main patterns for handling long-running operations: synchronous blocking (almost always wrong), the 202 Accepted + polling pattern, webhooks and callbacks, and server-sent events. The decision between them is architectural, and getting it wrong means brittle clients, unnecessary load, or a support queue full of "why is my request hanging?" tickets. For developers who want to see these patterns fully implemented in a production codebase — including error handling, retry logic, and state machine design — the complete source code is available on Patreon, where each pattern maps directly to a real enterprise use case.
Understanding the tradeoffs between these patterns is exactly the kind of decision covered in the ASP.NET Core Web API: Zero to Production course — specifically in the chapter on background jobs and long-running tasks, which walks through how BackgroundService, System.Threading.Channels, and durable job systems fit together in a single production API.

The architectural stakes are real: synchronous operations held open for more than a few seconds create thread pressure, trigger client-side timeouts, and make your API fragile to network interruptions. The patterns in this guide are how teams at scale solve this problem — and they are simpler to implement correctly than most developers expect.
Why Synchronous HTTP Breaks Under Load
The default ASP.NET Core request model assigns one thread per request. That thread is occupied for the entire duration of the operation. For a request that completes in under 500ms, this is unnoticeable. For a request that runs for 30 seconds or more, it is a performance tax that compounds under load.
Beyond thread exhaustion, clients have their own timeouts. A browser defaults to no HTTP timeout, but most HTTP clients — including HttpClient in .NET — apply one. Mobile clients in particular have aggressive timeouts enforced by the operating system. A synchronous endpoint that sometimes completes in 10 seconds and sometimes in 90 seconds is an endpoint that fails unpredictably for a large fraction of clients.
The solution is not to increase timeouts. Timeouts are a symptom of the wrong design, not a tunable parameter.
What Makes an Operation "Long-Running"?
There is no universal threshold, but the practical rule is: if an operation can exceed 5–10 seconds under realistic load, treat it as long-running by design. Operations that consistently fall in this range include:
- Report generation across large datasets
- File format conversion (PDF rendering, image processing, video transcoding)
- Batch record imports with validation
- Outbound integrations that call slow third-party APIs
- Machine learning inference pipelines
- Complex search or aggregation queries over cold data
Operations that are variable — fast under normal load, slow during spikes — also qualify, because you cannot safely design around the optimistic case.
The Four Patterns
Pattern 1: 202 Accepted + Status Polling
This is the most broadly applicable pattern for enterprise APIs. The client submits a request, receives an immediate 202 Accepted response with a Location header pointing to a status endpoint, and polls that endpoint until the operation completes.
The shape of the interaction is:
POST /reports→202 Accepted,Location: /reports/jobs/{jobId}GET /reports/jobs/{jobId}→{"status": "processing", "percentComplete": 35}GET /reports/jobs/{jobId}→{"status": "completed", "resultUrl": "/reports/{id}"}
The server side involves three components: the submission endpoint (which enqueues the job and returns 202), a background processor (which does the actual work and updates state), and the status endpoint (which reads current state from a shared store like a database or Redis).
When to use it:
- The client is a service or mobile app that can be written to poll
- Operations run for seconds to minutes
- The result must be retrievable after completion
- You need job history or auditability
When to avoid it:
- The client is a browser performing a user-triggered action where real-time feedback is essential
- The operation completes in under 2 seconds under load — polling adds unnecessary roundtrips
- You cannot accept the polling overhead on the status endpoint under high job submission rates
Anti-patterns: Returning 200 OK with a job ID instead of 202 Accepted confuses clients about what actually happened. Not including a Retry-After header leaves clients guessing how frequently to poll. Storing job state only in memory means a server restart loses all in-flight job status.
Pattern 2: Webhooks and Callbacks
Webhooks invert the polling model: instead of the client repeatedly asking "are you done?", the server pushes a notification when the operation completes. The client registers a callback URL at job submission time, and the server makes an HTTP POST to that URL when the result is ready.
When to use it:
- The client is another server-side system that can receive inbound HTTP
- Operations run for minutes to hours (polling at this scale is wasteful)
- Reliability is critical — you need delivery guarantees, retry logic, and dead-letter queues
- Integration with third-party systems that already use webhook conventions
When to avoid it:
- The client is a browser or mobile app that cannot expose a public endpoint
- The environment does not permit inbound connections to client systems
- You cannot implement webhook retry and signature verification — insecure or unreliable webhook delivery is worse than polling
Critical implementation detail: Webhooks without HMAC signature verification are a security vulnerability. Every webhook payload should include a signature that the receiving system can validate against a shared secret. Without this, any actor who discovers a webhook endpoint can inject arbitrary payloads.
For the architectural decision between webhooks and polling in durable workflows, the Inbox Pattern in ASP.NET Core covers how to make webhook delivery reliable at the receiving end.
Pattern 3: Server-Sent Events (SSE)
Server-Sent Events allow the server to push a stream of progress updates to a browser client over a single long-lived HTTP connection. Unlike WebSockets, SSE is unidirectional (server to client), which makes it simpler to implement and sufficient for the progress-reporting use case.
In ASP.NET Core, SSE is implemented by returning a response with Content-Type: text/event-stream and writing progress events to the response stream without closing it. The browser's EventSource API handles reconnection automatically.
When to use it:
- The client is a browser performing a user-triggered action that needs visible progress
- You want to avoid the complexity of WebSockets for a unidirectional feed
- Operations run for seconds to a few minutes — SSE connections held open for longer introduce load balancer and proxy timeout risk
When to avoid it:
- Your infrastructure includes load balancers or reverse proxies with aggressive connection timeouts
- You need bidirectional communication — SSE cannot send data back to the server
- Clients are mobile apps or services — SSE is a browser-native pattern; other clients can poll more efficiently
Pattern 4: Fire-and-Forget with In-Process Queue (and Why It Is Risky)
The simplest implementation is Task.Run or enqueuing work into IBackgroundTaskQueue and returning immediately. This works for low-stakes, best-effort operations where losing in-flight work on server restart is acceptable.
When this is acceptable:
- Sending a welcome email
- Updating a non-critical analytics counter
- Triggering a cache invalidation
When this is not acceptable:
- Payment processing
- Inventory reservation
- Any operation where the user expects a guaranteed outcome
The risk is straightforward: if the application restarts, recycles, or crashes between accepting the request and completing the work, that work is silently lost. There is no retry, no dead-letter queue, no audit trail. For enterprise systems, this is almost never acceptable for user-triggered operations.
The Decision Matrix
| Factor | 202 + Polling | Webhooks | SSE | Fire-and-Forget |
|---|---|---|---|---|
| Client type | Any | Server-to-server | Browser | Any |
| Duration | Seconds–minutes | Minutes–hours | Seconds–minutes | Best-effort only |
| Reliability | High (with DB state) | High (with retry) | Medium | Low |
| Complexity | Medium | High | Medium | Low |
| Browser-native | Yes | No | Yes | Yes |
| Audit trail | Yes | Yes | No (unless logged) | No |
What About Durable Jobs (Hangfire, Quartz)?
For the background processor in the 202 + Polling pattern, the question of in-process vs durable job store is worth calling out explicitly. A BackgroundService with System.Threading.Channels is lightweight and sufficient for short-lived work where loss on restart is tolerable. Hangfire or Quartz with a SQL/Redis backing store adds durability, retry, and a monitoring dashboard — essential when job completion carries business weight.
The ASP.NET Core Request Timeout Strategy guide is a useful companion here: it covers how CancellationToken propagation interacts with the decision to move work off the request thread.
Common Mistakes Enterprise Teams Make
1. Synchronous facades over async operations. Wrapping an async job in a synchronous-looking API — by blocking the request thread until the job completes — defeats the entire purpose. The client sees a long-hanging request; the server burns threads.
2. In-memory state for job tracking. Storing job status in a ConcurrentDictionary on the application instance means a pod restart, load balancer failover, or autoscaling event wipes all in-flight job state. Always persist job state to a durable store.
3. No Retry-After header on 202 responses. Clients that poll aggressively can create significant unnecessary load on the status endpoint. The Retry-After header tells the client exactly how long to wait before the next poll, and most well-implemented clients will honour it.
4. Webhook delivery without retry. A webhook delivery that fails because the receiving server is briefly unavailable silently loses the notification. Enterprise webhook implementations need exponential backoff retry, a dead-letter mechanism, and delivery confirmation.
5. Treating SSE as a durable message channel. SSE connections drop on network interruptions or proxy timeouts. The EventSource API reconnects automatically, but any events missed during the gap are lost unless the server implements event ID tracking and the client uses the Last-Event-ID header to resume.
How to Choose
Use 202 Accepted + Polling as the default for any service-to-service or mobile API operation that exceeds 5 seconds. It is reliable, simple to reason about, and works across all client types.
Add Webhooks when the operation duration makes polling uneconomical (minutes or more), or when your integration partners already expect webhook delivery.
Use SSE when the client is a browser and the UX requires visible progress feedback rather than a spinner with a status check button.
Use Fire-and-Forget only for genuinely low-stakes, non-critical side effects where silent loss is acceptable — and document that decision explicitly so the next developer does not accidentally apply this pattern to something that matters.
☕ Prefer a one-time tip? Buy us a coffee — every bit helps keep the content coming!
FAQ
What HTTP status code should a long-running API operation return?
Return 202 Accepted. This status code signals that the request has been received and accepted for processing, but the processing has not completed. Include a Location header pointing to a status endpoint where the client can check progress.
How often should a client poll the status endpoint?
The server should include a Retry-After header in the 202 Accepted response and in each polling response where the operation is still in progress. A reasonable default is 5–10 seconds for operations expected to complete in under a minute, and 30–60 seconds for longer operations. Clients that ignore Retry-After and poll aggressively can overwhelm status endpoints under high job submission rates.
Is it safe to use Task.Run for long-running operations in ASP.NET Core?
No, for any operation where completion matters. Task.Run schedules work on the thread pool without any lifecycle management. If the application recycles or the process is killed, that work is silently abandoned. Use a BackgroundService with a durable queue for anything where loss is unacceptable.
When should I use Hangfire instead of a BackgroundService?
Use Hangfire (or Quartz.NET) when you need job persistence across restarts, retry on failure, scheduled recurring jobs, or a monitoring dashboard. Use BackgroundService with System.Threading.Channels for in-process coordination where the work is lightweight, short-lived, and loss-tolerant.
Can I use SSE in ASP.NET Core with load balancing?
Yes, but with care. SSE holds open an HTTP connection for the duration of the stream. Many load balancers and reverse proxies (including Nginx and Azure Application Gateway) have default idle connection timeouts of 60–120 seconds. If your operations run longer than that, SSE connections will be closed. Configure proxy_read_timeout in Nginx or the equivalent in your proxy. Alternatively, emit keep-alive events from the server every 30 seconds to prevent idle timeout disconnects.
What is the difference between webhooks and polling for long-running operations? Polling is client-initiated: the client periodically checks whether the operation is complete. Webhooks are server-initiated: the server pushes a notification to the client's registered callback URL when the operation finishes. Polling is universally applicable (works for any client type) but consumes network and compute resources for every check. Webhooks are more efficient for long-duration operations but require the client to expose a public HTTPS endpoint and implement payload signature verification.
How do I handle long-running operations across microservices in .NET? The most robust approach is to use a message broker (RabbitMQ, Azure Service Bus, Kafka) to decouple the request submission from the execution. The API publishes a command message, a separate service consumes it, updates a shared job state store, and either polls or pushes the result. This pattern scales independently and survives partial service restarts. For the receiving side of the notification, the Inbox Pattern prevents duplicate processing.