

The RAG Pattern in ASP.NET Core: When to Use It and How
Most LLMs are remarkably good at answering general questions - and reliably wrong about your product. Asking GPT-4o or Llama 3 about your internal refund policy, your API error codes, or the features you shipped last quarter gets you confident-sounding answers pulled from a training set that does not contain your data. That gap is exactly what Retrieval-Augmented Generation (RAG) closes.
The full implementation - with ingestion pipeline, vector search, grounded prompts, citation handling, and a working test suite - is available on Patreon, where you can run it against your own knowledge base straight away.
Understanding RAG in isolation is useful, but seeing it assembled inside a real production API - with chunking strategies, token budgeting, and failure handling already connected - is what makes it land. Chapters 9 and 10 of the AI-Powered .NET APIs course build exactly that: a grounded support-desk API in C# from ingestion to shipped endpoint, with citations and a "I don't know" refusal path included.

What Problem Does RAG Actually Solve?
LLMs are frozen at their training cut-off. They know nothing about your product documentation, your internal runbooks, your customer records, or the pull request you merged this morning. Fine-tuning is one answer, but it is expensive, slow to update, and it bakes data into model weights in a way that is hard to audit or revoke.
RAG takes a different approach: instead of teaching the model your data, you fetch the right pieces of data at query time and hand them to the model as context alongside the question. The model then generates an answer grounded in real, current information from your systems - information you control, can update instantly, and can cite back to the user.
In production I have seen this pattern eliminate entire categories of hallucination for support-desk APIs. A model that was confidently fabricating feature details started citing the exact paragraph in the documentation that answered the question - because that paragraph was now in the prompt.
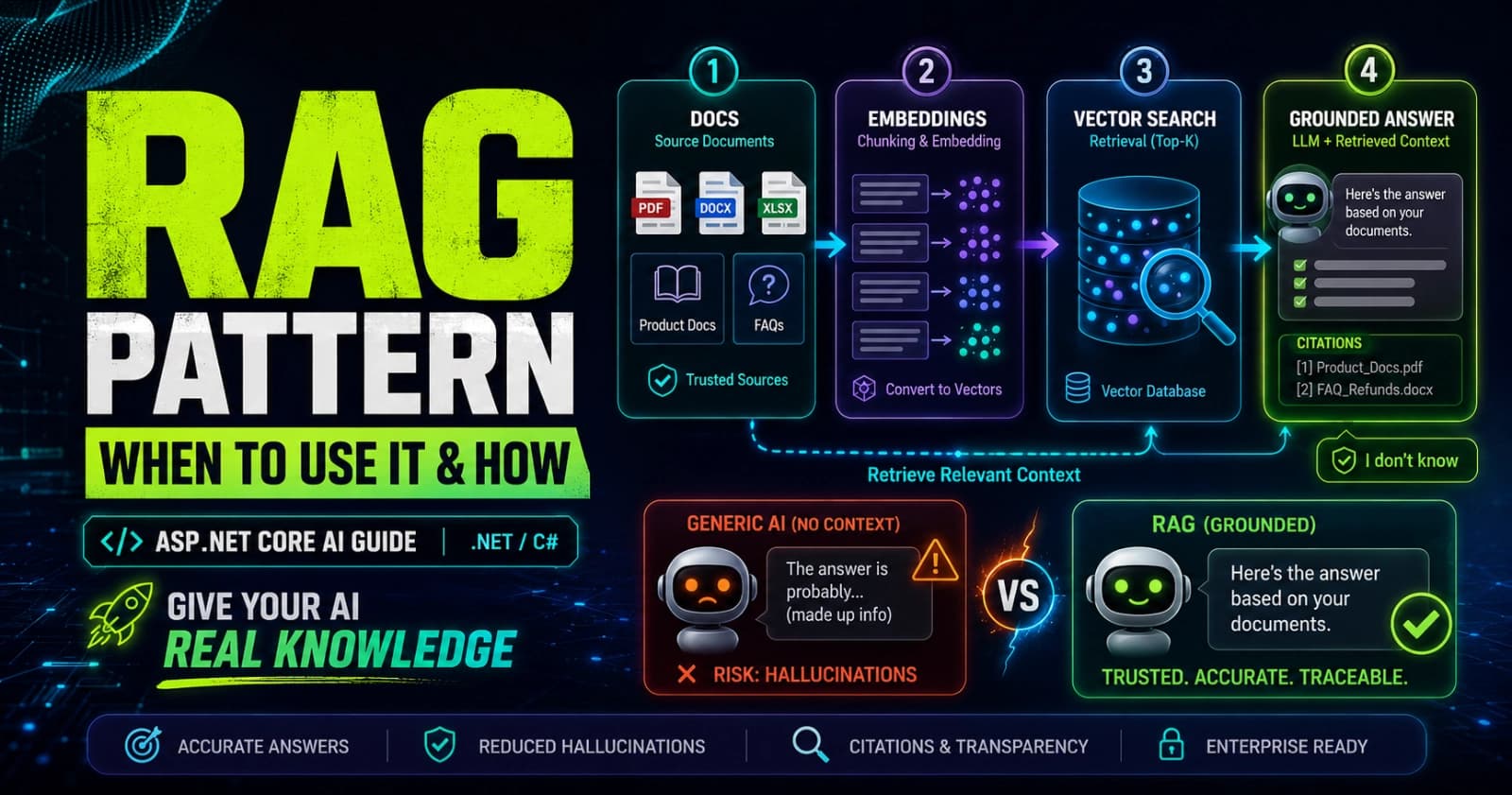
The Core Flow: Five Steps
RAG has two distinct phases: ingestion (run once, or on a schedule) and retrieval (run per query).
Ingestion:
Load your documents (product docs, FAQs, runbooks, etc.)
Split them into chunks - typically 300-600 tokens with some overlap
Generate an embedding vector for each chunk using
IEmbeddingGeneratorStore the chunk text and its vector in a vector store
Retrieval:
Embed the user's question using the same model
Run a vector similarity search to find the top-k most relevant chunks
Inject those chunks into the prompt as context
Send the augmented prompt to the LLM
Return the grounded answer (optionally with citations)
That is the whole loop. The power is in step 3 on the ingestion side - the semantic search that finds relevant chunks even when the user does not use the exact words from the documentation.
When RAG Is the Right Pattern
RAG fits well when all of the following are true:
Your knowledge base changes regularly. If the data is static and small (say, a 20-page policy document that never changes), you could just include it in every system prompt. RAG becomes worth the infrastructure cost when your knowledge base grows, updates frequently, or both.
The model needs to answer questions about proprietary data. Internal APIs, product catalogues, legal documents, support tickets - anything the model has never been trained on and that you cannot upload to a third-party fine-tuning pipeline.
Answers need to be auditable. A retrieved chunk is a citation. You can show the user exactly which source paragraph produced the answer. Fine-tuned models cannot do this - you cannot trace an answer back to a specific training document.
You cannot afford to re-train or re-fine-tune on every update. A RAG pipeline ingests a new document in seconds. A fine-tuning run takes hours and dollars.
When RAG Is Not the Right Pattern
RAG adds real moving parts: an embedding model, a vector store, a chunking strategy, a retrieval step, token-budget management, and a grounding prompt. That is complexity worth paying when the pattern fits - but not when it does not.
Skip RAG when:
Your data is tiny and static. A 500-word FAQ that never changes belongs in the system prompt, not a vector store.
You are answering general-knowledge questions. If the question does not require proprietary context, plain LLM inference is faster, cheaper, and equally good.
You need structured data lookups. Asking "what is the current order status for order #4821" is a database query, not a semantic search. RAG is not a substitute for a well-designed tool call or a direct DB query from an agent.
Your team does not yet have a production embedding model. Running a RAG pipeline on an inconsistent or frequently-swapped embedding model breaks retrieval silently - score thresholds drift, old vectors become incompatible, searches return garbage. Stabilise the embedding model first.
Implementation Sketch with Microsoft.Extensions.AI
The .NET AI building blocks make the plumbing reasonably clean. IEmbeddingGenerator<TInput, TEmbedding> is the abstraction for generating vectors, and Microsoft.Extensions.VectorData provides IVectorStore as the provider-agnostic interface for storing and searching them.
A minimal ingestion step looks like this:
// Register in DI - provider swap is a one-liner
builder.Services.AddOllamaEmbeddingGenerator(
new Uri("http://localhost:11434"), "nomic-embed-text");
builder.Services.AddSqliteVectorStore("knowledge.db");
At ingestion time, you generate the embedding and upsert:
var embedding = await embeddingGenerator
.GenerateEmbeddingVectorAsync(chunk.Text, cancellationToken: ct);
await vectorCollection.UpsertAsync(new KnowledgeChunk
{
Id = chunk.Id,
Text = chunk.Text,
SourceUrl = chunk.SourceUrl,
Vector = embedding
}, cancellationToken: ct);
At query time, you embed the question, search, then build the grounded prompt:
var queryVector = await embeddingGenerator
.GenerateEmbeddingVectorAsync(question, cancellationToken: ct);
var results = await vectorCollection
.VectorizedSearchAsync(queryVector, new() { Top = 5 }, ct);
// Build context from retrieved chunks
var context = string.Join("\n\n", results.Results
.Select(r => r.Record.Text));
The context goes into the system prompt alongside an instruction to only answer from the provided material - and to say "I don't know" if the answer is not there.
These snippets show the shape of the flow. The complete implementation - chunking strategies, overlap handling, score-threshold filtering, citation extraction, the "I don't know" path, and token-budget enforcement - is what the course chapters walk through in full.
Trade-offs Worth Knowing Before You Commit
Chunk size is a real trade-off. Small chunks (150-200 tokens) retrieve precisely but may lack surrounding context. Large chunks (800-1000 tokens) carry more context but consume your token budget faster and reduce retrieval precision. In production we landed on 400 tokens with 10% overlap as a reasonable default - then tuned per knowledge base.
Embedding model consistency matters more than you think. The vectors you store during ingestion and the vector you generate at query time must come from the same model. Swapping embedding models means re-ingesting your entire knowledge base. Plan for this upfront.
Top-k thresholds need tuning. Returning too many chunks bloats the prompt and dilutes relevance. Too few and you miss important context. Score thresholds - not just top-k counts - help here: discard results below a minimum similarity score so you're not injecting noise into the prompt.
RAG does not fix a bad knowledge base. Outdated, contradictory, or poorly structured source documents produce confidently grounded wrong answers. The ingestion pipeline quality ceiling is the answer quality ceiling.
Hybrid search is often better. Semantic search alone misses exact-match cases - product codes, error numbers, named entities. A hybrid approach (semantic + BM25 keyword) catches both. Microsoft.Extensions.VectorData supports hybrid search in providers that offer it; worth evaluating early.
For a deeper look at how the RAG pattern intersects with prompt injection risks - specifically the poisoned-document attack - see the post on preventing prompt injection in ASP.NET Core AI APIs for the defensive patterns to layer on top.
The foundation of the RAG infrastructure - the IChatClient and IEmbeddingGenerator abstractions, provider configuration, and the .NET AI landscape in general - is covered in What's New in .NET 10 AI Integration: Microsoft.Extensions.AI and IChatClient if you are coming to this fresh.
FAQ
What is the RAG pattern in ASP.NET Core?
RAG (Retrieval-Augmented Generation) is an architecture pattern where relevant documents or knowledge chunks are retrieved from a vector store at query time and injected into the LLM prompt as context. In ASP.NET Core, this is typically built using IEmbeddingGenerator and IVectorStore from Microsoft.Extensions.AI and Microsoft.Extensions.VectorData, wired into an API endpoint that handles both the retrieval and the LLM call in a single request.
Does RAG require a paid embedding API?
No. With Ollama running locally, you can use open-source embedding models like nomic-embed-text or mxbai-embed-large at no cost. The IEmbeddingGenerator abstraction in Microsoft.Extensions.AI makes swapping between a local Ollama model and a cloud provider (OpenAI, Azure OpenAI) a one-line DI configuration change - so you develop locally for free and deploy against a cloud provider when needed.
What vector store should I use in development vs production?
For local development and small production deployments, sqlite-vec is a solid choice - zero infrastructure, embedded in-process, and supported by Microsoft.Extensions.VectorData. For higher-scale production, SQL Server 2025 (native vector type), Qdrant, or pgvector are common choices. The IVectorStore abstraction means the application code does not change when you swap the backing store.
How do I handle the case where RAG cannot find a relevant answer?
Set a minimum similarity score threshold on your vector search results - for example, discard any result below 0.70 cosine similarity. If no results clear the threshold, the system prompt should instruct the model to respond with something like "I don't have enough information to answer that reliably." This "I don't know" path is critical for user trust: a model that refuses to guess is more useful than one that confidently fabricates.
When should I use RAG versus fine-tuning?
Use RAG when your knowledge base changes frequently, you need audit trails or citations, or you cannot afford the cost and time of re-training. Fine-tuning is better when you need the model to adopt a specific tone, style, or output format consistently - not when you need it to know specific facts. In practice, most enterprise use cases are better served by RAG or a RAG-plus-fine-tuning combination than by fine-tuning alone.
Is RAG affected by the LLM's context window size?
Yes, directly. The retrieved chunks and the user question must both fit within the model's context window, alongside the system prompt. With a 128k-token context window (common in modern models), this is rarely a bottleneck - but with smaller edge models it matters. Token budget enforcement - counting tokens before sending, trimming low-scoring chunks if the budget is exceeded - is an important production safeguard.
About the Author
I'm Celin Daniel, Co-founder of Coding Droplets. I've been building .NET and ASP.NET Core systems in production for 13+ years - APIs, distributed backends, enterprise platforms. Everything I write here comes from real shipping experience: patterns that held up, trade-offs that bit us, and lessons learned the hard way.
GitHub: codingdroplets
YouTube: Coding Droplets
Website: codingdroplets.com



