

How to Stream LLM Responses in ASP.NET Core with IChatClient
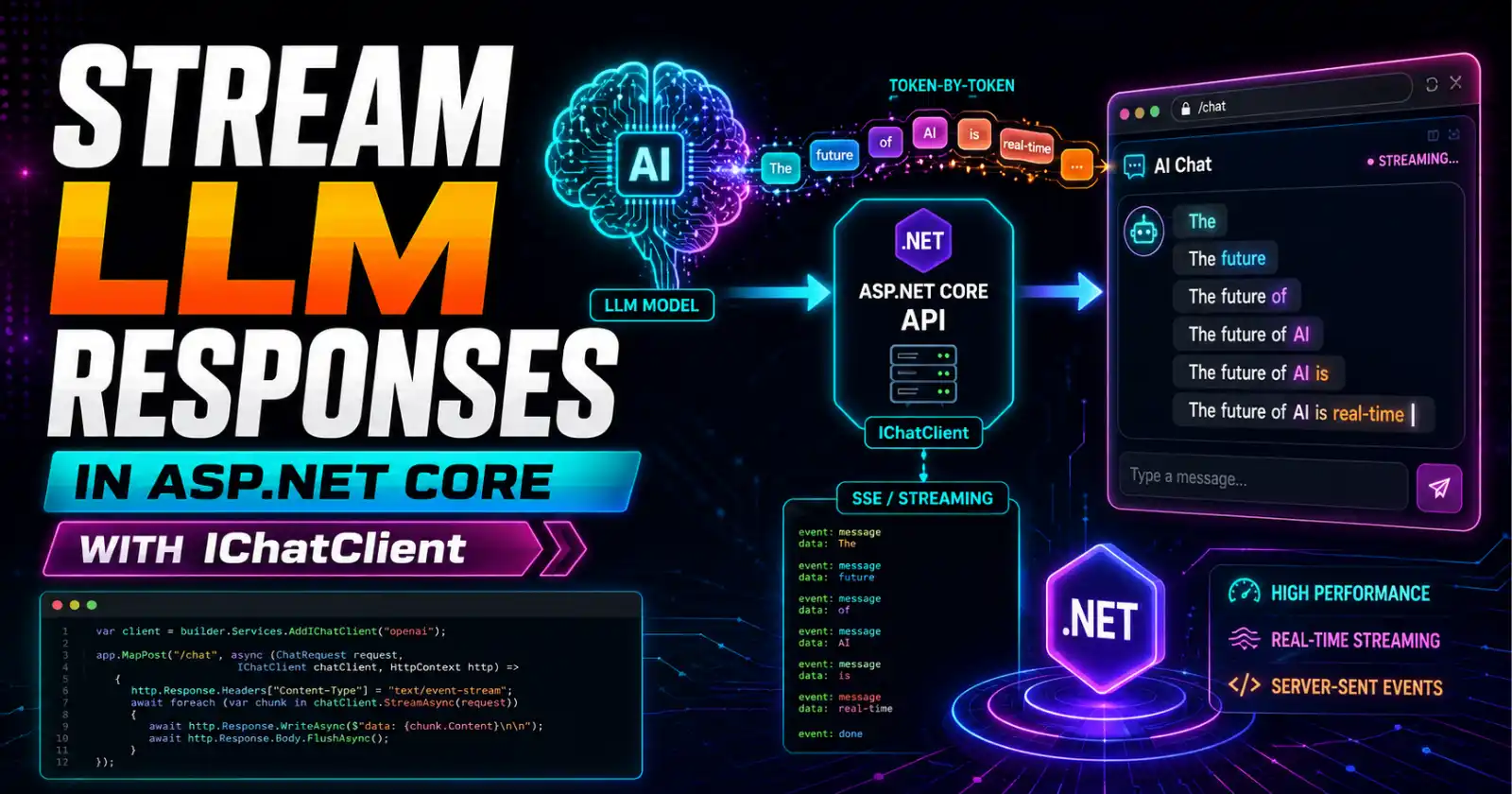
The first time I shipped an AI endpoint that returned a full paragraph in one POST, the support channel lit up within a day. Nobody complained that the answer was wrong. They complained that the request "hung" for eight seconds and then dumped everything at once. That is the core reason for streaming LLM responses in ASP.NET Core: users will happily read output as it arrives, but they abandon a spinner that sits still. A model that takes six seconds to finish feels instant when the first words appear in 300 milliseconds. This walkthrough is the pattern I actually ship, built on IChatClient from Microsoft.Extensions.AI and Server-Sent Events, with the production edges that bit us along the way.
If you want the complete, runnable version - the full endpoint, the client-side reader, cancellation wired end to end, and a fallback for older runtimes - the annotated source lives on Patreon, ready to clone and adapt. Streaming is also one of those features where the plumbing is easy but the trade-offs are not obvious until you hit them in production. Getting it right means handling cancellation, back-pressure, and partial responses at the same time, and that is exactly what Chapter 5 of the AI-Powered .NET APIs course walks through inside one running support API - from the first token to a shipped endpoint.

Why Streaming Changes the User Experience
Large language models generate one token at a time. A non-streamed endpoint hides that: it waits for the model to finish, buffers the whole completion, then sends it. The user stares at nothing until the last token lands. Streaming flips this. The moment the model produces its first token, you push it to the client, and perceived latency collapses to time-to-first-token instead of time-to-full-response.
This is not a cosmetic tweak. In production I have seen the same model, on the same hardware, feel "broken" when buffered and "fast" when streamed, with zero change to actual generation speed. If your AI feature has any interactive surface - a chat box, an inline assistant, a summarizer - streaming is the difference between something people use and something they close.
The Building Block: IChatClient and GetStreamingResponseAsync
Microsoft.Extensions.AI gives you a provider-neutral abstraction, IChatClient. You register it once and inject it anywhere, and the same code runs against Ollama, GitHub Models, OpenAI, or Azure OpenAI with a one-line registration change. If you are new to the abstraction, start with our overview of Microsoft.Extensions.AI and IChatClient in .NET 10, then come back here for the streaming path.
Registration is a single call in Program.cs. Here is the OpenAI-backed shape (swap the provider and the rest of the app does not change):
// Requires Microsoft.Extensions.AI 9.x+ (the .NET 10 GA wave)
builder.Services.AddChatClient(
new OpenAIClient(apiKey).GetChatClient("gpt-4o-mini").AsIChatClient());
The streaming method itself is GetStreamingResponseAsync. It takes the same inputs as GetResponseAsync but, instead of a single ChatResponse, it returns an IAsyncEnumerable<ChatResponseUpdate> - a stream of partial updates that together form one answer:
await foreach (ChatResponseUpdate update in
chatClient.GetStreamingResponseAsync(userMessage, cancellationToken: ct))
{
// update.Text holds the newest chunk of generated text
yield return update.Text;
}
A version gotcha worth calling out. In earlier previews this method was named CompleteStreamingAsync and returned IAsyncEnumerable<StreamingChatCompletionUpdate>. If your code or a tutorial you are copying references CompleteStreamingAsync, you are on an old preview. The current stable API is GetStreamingResponseAsync returning IAsyncEnumerable<ChatResponseUpdate>. This single rename is behind a surprising amount of "method not found" confusion, so update the call and the type together. The official IChatClient documentation tracks the current surface.
What Is the Difference Between GetResponseAsync and GetStreamingResponseAsync?
GetResponseAsync returns one ChatResponse after the model finishes generating - simple, but the caller waits for the whole thing. GetStreamingResponseAsync returns an IAsyncEnumerable<ChatResponseUpdate> that yields text as it is produced, so you can forward each chunk to the client immediately. Use the non-streaming call for short, background, or tool-style requests where nobody is watching; use the streaming call for any user-facing generation where perceived latency matters.
Design Decisions Before You Stream
Before wiring code, decide how the stream reaches the browser. There are three common transports, and for token-by-token text from a single server to a single client, Server-Sent Events (SSE) is almost always the right call. SSE is one-directional (server to client), rides a plain HTTP connection, and reconnects automatically - which fits AI output perfectly. WebSockets and SignalR are heavier tools built for bidirectional, multi-client scenarios. I unpack the full trade-off in Server-Sent Events vs SignalR vs WebSockets, but the short version is: for a chat completion stream, reach for SSE first.
The second decision is where the model call lives. Never call the model from the frontend - your API key would leak instantly. The browser talks to your ASP.NET Core endpoint, and only your server talks to the model. Streaming does not change that boundary; it just keeps the connection open while tokens flow through it.
Streaming to the Browser with Native SSE in .NET 10
Here is where .NET 10 makes life much easier. ASP.NET Core 10 added native Server-Sent Events support through TypedResults.ServerSentEvents (and Results.ServerSentEvents), which turns any IAsyncEnumerable<T> into a correctly framed event stream. The runtime sets the text/event-stream content type, handles flushing, and keeps the connection open for you. No manual header juggling.
The endpoint becomes small. A helper method adapts the model stream into a sequence of strings, and the result type does the rest:
// .NET 10 / ASP.NET Core 10 - native SSE
app.MapPost("/chat/stream", (ChatRequest req, IChatClient chat, CancellationToken ct) =>
TypedResults.ServerSentEvents(StreamTokens(chat, req.Message, ct), eventType: "token"));
static async IAsyncEnumerable<string> StreamTokens(
IChatClient chat, string message,
[EnumeratorCancellation] CancellationToken ct)
{
await foreach (var update in chat.GetStreamingResponseAsync(message, cancellationToken: ct))
{
if (!string.IsNullOrEmpty(update.Text))
yield return update.Text;
}
}
Two details that matter: the [EnumeratorCancellation] attribute (from System.Runtime.CompilerServices) is what lets the request's CancellationToken actually flow into the await foreach, and skipping empty update.Text values avoids sending noise events, since some updates carry metadata rather than text. If you want the wider picture on what else shipped, see our notes on ASP.NET Core 10 minimal API improvements including SSE.
On the client, an EventSource (or a fetch reader) appends each token event to the DOM as it arrives. That is the entire "typewriter" effect - no framework required.
Streaming Before .NET 10
If you are still on .NET 8 or .NET 9, you do not get the native helper, but the pattern is the same. Set the response headers yourself, then write and flush each chunk:
// .NET 8/9 fallback - manual SSE
Response.Headers.ContentType = "text/event-stream";
await foreach (var update in chat.GetStreamingResponseAsync(message, cancellationToken: ct))
{
await Response.WriteAsync($"data: {update.Text}\n\n", ct);
await Response.Body.FlushAsync(ct);
}
The explicit FlushAsync is the important part - without it, buffering can hold your tokens hostage and defeat the whole point of streaming.
Handling Cancellation and Timeouts
This is the part most demos skip and production punishes. When a user closes the tab or hits stop, you want the model call to stop too - otherwise you keep paying for tokens nobody will read. Because the request's CancellationToken flows all the way into GetStreamingResponseAsync, a dropped connection cancels the enumeration, which cancels the upstream model request. That chain only works if you thread the token through every layer, which is why the [EnumeratorCancellation] attribute above is not optional.
Add a ceiling as well. A misbehaving model or a slow provider can stream slowly forever, so I wrap long-running AI calls with a request timeout policy. Runaway generation is also a direct cost problem - I dug into that failure mode in Runaway LLM Costs in a .NET API. Cancellation and timeouts are not edge cases here; they are load-bearing.
Trade-offs and Gotchas From Production
Buffering middleware and proxies. Response compression, output caching, or a reverse proxy that buffers will collapse your stream back into one big payload. Exclude the streaming route from compression and confirm your proxy (Nginx, YARP, a CDN) is not buffering
text/event-stream.You cannot change status codes mid-stream. Once the first byte is written, the response has started and the status line is locked. Validate input and check auth before you begin streaming, not during it.
Errors after the first token are awkward. If the model faults halfway, you have already sent a
200. Emit a dedicatederrorevent so the client can react gracefully instead of silently truncating.Structured output and streaming pull in opposite directions. If you need a validated JSON object back, streaming half-formed JSON is not useful. Stream free text; buffer when you need a typed result.
What to Do Next
Start by converting one interactive endpoint to GetStreamingResponseAsync behind SSE, then layer in cancellation and a timeout, and only after that worry about reconnection and error events. The wins are immediate: the same model feels dramatically faster the moment the first token hits the screen. Keep the model call server-side, keep the token flowing to the browser, and let IChatClient stay provider-neutral so you can swap models without touching the endpoint.
Frequently Asked Questions
How Do I Stream LLM Responses in ASP.NET Core With IChatClient?
Inject IChatClient from Microsoft.Extensions.AI, call GetStreamingResponseAsync, and forward each ChatResponseUpdate.Text to the client. On .NET 10, wrap the token sequence in TypedResults.ServerSentEvents so the framework handles the text/event-stream framing and flushing. On .NET 8 or 9, set the content type manually and call FlushAsync after each write.
Why Is My IChatClient Not Streaming Token by Token?
The most common cause is buffering somewhere in the pipeline - response compression, output caching, or a reverse proxy holding the response. Exclude the streaming route from compression and make sure your proxy does not buffer text/event-stream. The second most common cause is missing an explicit flush on pre-.NET-10 manual SSE.
What Happened to CompleteStreamingAsync in Microsoft.Extensions.AI?
It was renamed. Earlier previews used CompleteStreamingAsync returning IAsyncEnumerable<StreamingChatCompletionUpdate>. The current stable API is GetStreamingResponseAsync returning IAsyncEnumerable<ChatResponseUpdate>. If you see CompleteStreamingAsync, upgrade the package and update both the method name and the update type.
Should I Use Server-Sent Events, SignalR, or WebSockets for LLM Streaming?
For one-directional token streaming from your server to a single client, Server-Sent Events is the simplest correct choice: plain HTTP, automatic reconnection, and native support in .NET 10. Reach for SignalR or WebSockets only when you genuinely need bidirectional or multi-client real-time messaging.
How Do I Stop the Model From Generating When a User Cancels?
Thread the request's CancellationToken into GetStreamingResponseAsync and mark your streaming iterator parameter with [EnumeratorCancellation]. When the client disconnects, ASP.NET Core cancels the token, the await foreach stops, and the upstream model request is cancelled - so you stop paying for tokens nobody will see.
About the Author
I'm Celin Daniel, Co-founder of Coding Droplets. I've been building .NET and ASP.NET Core systems in production for 13+ years - APIs, distributed backends, enterprise platforms. Everything I write here comes from real shipping experience: patterns that held up, trade-offs that bit us, and lessons learned the hard way.
GitHub: codingdroplets
YouTube: Coding Droplets
Website: codingdroplets.com



