

EF Core Connection Pool Exhaustion in ASP.NET Core: Root Cause and Fix
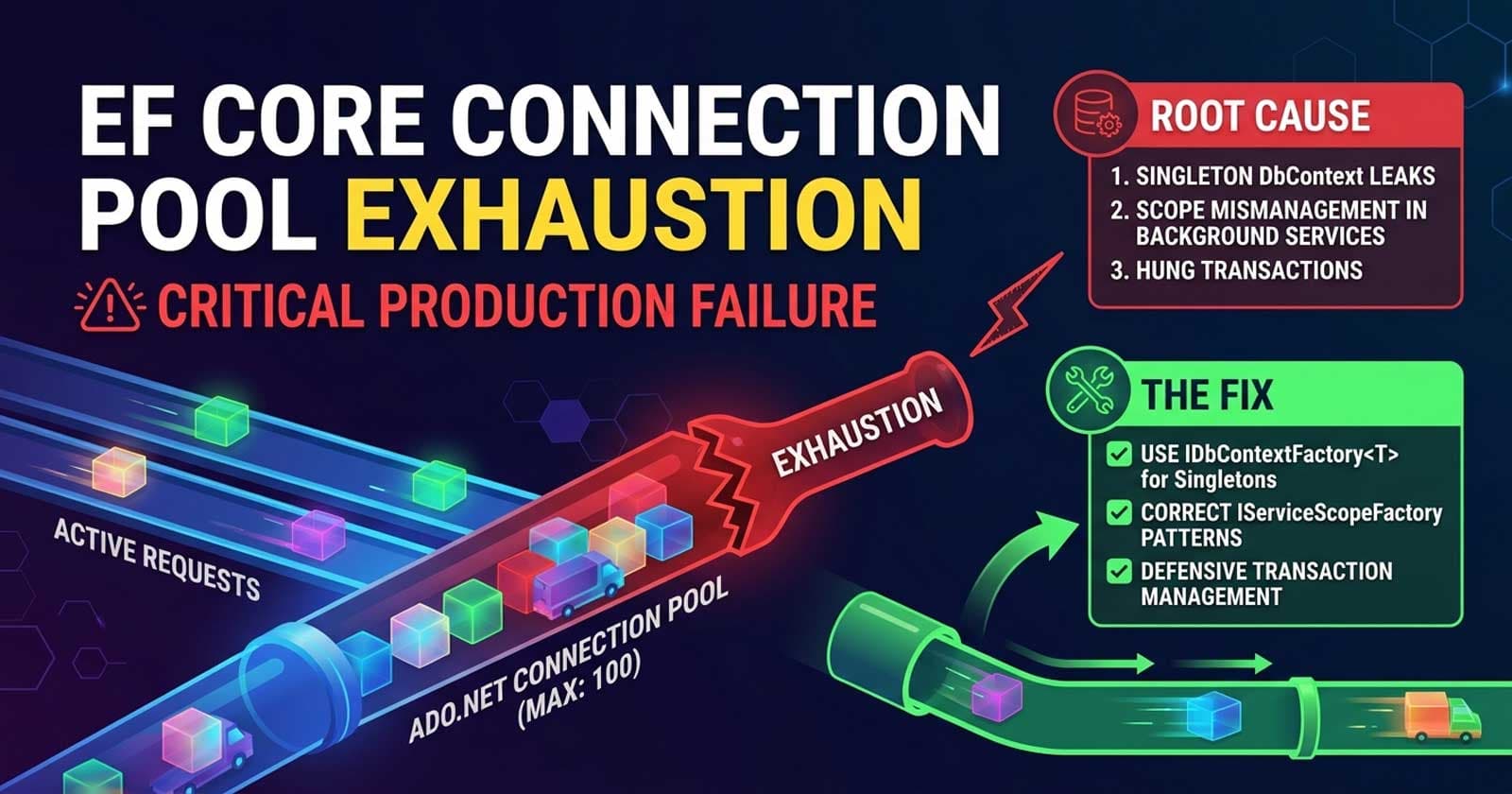
EF Core connection pool exhaustion is one of the most disruptive production failures a .NET team can face - the kind that hits under load, triggers cascading timeouts, and sends developers hunting through logs for an error message that offers very little context. The culprit is almost always a connection that was never returned to the pool, a DbContext outliving its intended scope, or a background service treating scoped database resources as if they were singletons. Understanding exactly why this happens - and how to prevent it recurring - is what separates teams that firefight incidents from teams that prevent them.
If you want to go deeper on the patterns covered here - including production-ready implementations of background services with proper scope management - the full working source code is on Patreon, with everything wired together the way enterprise teams actually ship it.
The fundamentals of why connection pool exhaustion happens are rooted in how .NET's DI lifetimes interact with EF Core's DbContext. If you're unfamiliar with how Singleton, Scoped, and Transient lifetimes behave in ASP.NET Core, this enterprise guide on DI lifetimes is worth reading first - it explains the lifetime mismatch problem that drives most of these failures. Understanding how scoped services interact with background workers also connects directly to background service patterns in .NET 10, where connection leaks from BackgroundService implementations are a recurring theme.

What Exactly Is the Connection Pool?
Before diagnosing exhaustion, it's worth understanding what the pool actually is. ADO.NET (and by extension, EF Core) maintains a connection pool per unique connection string. When your code "opens" a database connection, the driver checks whether a pooled connection is available. If yes, it reuses it. If no, it creates a new one - up to the pool's maximum size.
When Max Pool Size is reached and all pooled connections are in use, the next request to open a connection waits. If a connection doesn't become available within the configured timeout period, ADO.NET throws the error that most developers have seen at least once:
InvalidOperationException: Timeout expired. The timeout period elapsed prior to obtaining a connection from the pool.
The pool itself is healthy. The problem is upstream - something is holding connections open longer than it should.
How Does EF Core Use the Connection Pool?
EF Core opens a database connection lazily - when it actually needs to talk to the database. It closes (returns) that connection when the DbContext is disposed.
In a typical ASP.NET Core request, this lifecycle is clean: DbContext is scoped, the request scope is created at the start of the request and disposed at the end. The connection is held only for the duration of active database work, then returned to the pool automatically.
The problems start when DbContext escapes its intended scope - or when code outside the request pipeline tries to use it without properly managing scope boundaries.
Root Cause 1: DbContext Registered as Singleton (or Injected Into One)
The most common root cause. A DbContext registered as Singleton - or injected as a constructor dependency into a Singleton service - will live for the entire application lifetime. Its connection is held open indefinitely, never returned to the pool.
This can also happen indirectly: a Singleton service receives a Scoped DbContext via constructor injection. ASP.NET Core's DI system will either throw a validation error at startup (if scope validation is enabled) or silently capture the scoped instance inside the singleton - which means every request uses the same DbContext instance, and the connection is never properly cycled.
The fix is to never inject DbContext directly into a Singleton. Use IDbContextFactory<T> or resolve via IServiceScopeFactory at call time to get a fresh, scoped instance that lives only for the operation and is disposed immediately after.
Root Cause 2: Background Services Without Proper Scope Management
BackgroundService and IHostedService implementations run as singletons in the .NET host. If a background service injects DbContext directly via constructor - which is a scoped service - this creates the same lifetime mismatch described above.
The canonical fix here is IServiceScopeFactory. Injecting IServiceScopeFactory into the constructor is safe (it is itself a singleton). When the background task needs database access, it creates a scope, resolves the DbContext from within that scope, performs the operation, and disposes the scope immediately. This ensures the connection is returned to the pool after each unit of work - not held open for the service's entire lifetime.
Forgetting to dispose the scope, or holding onto the resolved DbContext reference outside the using block, is the most common mistake teams make when applying this pattern.
Root Cause 3: Long-Running Transactions That Are Never Committed or Rolled Back
A DbContext that has an open transaction holds its connection actively engaged. If a transaction is started but never committed or rolled back - because an exception was swallowed, a retry loop was implemented incorrectly, or the code simply forgot - the connection stays occupied in the pool.
Under low traffic this is survivable. Under sustained load, a handful of leaked transactions can exhaust the entire pool. The symptom is connections that show up as "active" in your database server's process list long after any legitimate request has completed.
The fix here is defensive transaction management: always use try/catch/finally patterns or using blocks that guarantee rollback on exception, and instrument your transaction durations to detect unusually long holds.
Root Cause 4: Queries That Hold Connections Across Async Boundaries
Streaming result sets with IAsyncEnumerable<T> or iterating a database query lazily can keep a connection open for the entire duration of the enumeration. If the consuming code awaits other work between iterations, or if the enumeration is never completed (e.g., the response was cancelled partway through), the connection stays open.
The connection is only released when the DbContext is disposed - not when the query command is issued. In high-concurrency APIs where partial reads are common (client disconnects, streaming responses), this can silently accumulate open connections.
Root Cause 5: AddDbContextPool Misconfiguration
EF Core's AddDbContextPool is a performance feature that maintains a pool of DbContext instances at the application level, on top of the connection pool maintained by ADO.NET. It is not a substitute for proper lifetime management - and misconfiguring it can actually make pool exhaustion worse.
If you are using AddDbContextPool with a pool size that is too small relative to your concurrency level, DbContext instances will be created fresh (with their own connections) when the pool is exhausted. This can mask the real problem and lead to confusion when tuning. The EF Core context pool and the ADO.NET connection pool operate at different layers, and adjusting one without understanding the other leads to surprises.
How to Diagnose Connection Pool Exhaustion in Production
The error message alone doesn't tell you where the leak is. Diagnosis requires correlating several signals:
Application logs: The InvalidOperationException timeout is the starting point. Look at the timestamps - are they correlated with a specific endpoint, background job trigger, or spike in concurrent requests?
Database server process list: Query sys.dm_exec_sessions (SQL Server) or pg_stat_activity (PostgreSQL) to see how many connections are currently open, which queries are running, and how long they have been active. Connections that have been idle for extended periods are typically leaked - they were never returned to the pool.
OpenTelemetry and metrics: The Microsoft.EntityFrameworkCore and System.Net.Http meter sources expose metrics for active connections. If you have OpenTelemetry configured (see Chapter 14 of the Zero to Production course for a complete setup), you can watch pool utilisation in real time and correlate spikes with specific operations.
Max Pool Size in the connection string: The ADO.NET default is 100 (SQL Server). Under genuine sustained load this may legitimately need increasing - but only after you have ruled out leaks. Increasing the pool size to compensate for leaked connections is a temporary band-aid that raises the ceiling without fixing the floor.
What Does a Correct Fix Look Like?
The corrective patterns converge on one principle: the DbContext must be created, used, and disposed within the smallest possible scope, with no references held across async boundaries or scope boundaries.
For background services: inject IServiceScopeFactory, create a scope per unit of work, resolve DbContext within that scope, use await correctly, and dispose the scope when the unit of work completes - always, even on exception.
For singleton services that need database access: use IDbContextFactory<T>. This factory is safe to inject into singletons. Each call to CreateDbContextAsync() returns a new, independent DbContext instance that you own and are responsible for disposing. It does not participate in DI scope management - you control its lifetime entirely.
For transaction management: instrument every transaction boundary. Log the transaction ID and duration at commit and rollback. Set a timeout on your transactions that is shorter than your ADO.NET connection timeout - a timed-out transaction will clean up its connection; a hung transaction holding a connection indefinitely will not.
Prevention Checklist
Before you ship code that touches EF Core in any non-request context, run through these:
Is the
DbContextregistered asScoped? (It should be, always - unless usingAddDbContextPool, which manages its own pooling.)Is any
Singletonservice receivingDbContextvia constructor injection? (If yes, refactor toIDbContextFactory<T>orIServiceScopeFactory.)Does every background service create a fresh scope per unit of work and dispose it in a
finallyblock?Are all database transactions explicitly committed or rolled back - with no code paths that can bypass the rollback?
Are there any unawaited async calls that could silently abandon in-progress database operations?
Is the connection pool size in the connection string appropriate for your concurrency level - and have you verified this against actual pool utilisation metrics, not just guessing?
The production codebase that implements all of these patterns cleanly - with background services, IDbContextFactory<T>, and transaction instrumentation - is available on Patreon for members who want to study and adapt a working reference implementation.
FAQ
Why does connection pool exhaustion only appear under load and not during local development?
Local development typically runs with low concurrency - one or two developers, sequential requests, no background jobs competing. The pool's default size of 100 connections comfortably handles a handful of concurrent users, even with leaks. Under production load with dozens or hundreds of concurrent requests, the same leaks that went unnoticed locally consume the pool within seconds.
What is the difference between the ADO.NET connection pool and EF Core's DbContext pool (AddDbContextPool)?
The ADO.NET connection pool is a driver-level feature that manages raw database connections. EF Core's DbContext pool (AddDbContextPool) is an application-level feature that maintains a pool of DbContext instances to avoid the overhead of re-initialising them per request. They operate at different layers. You can exhaust the DbContext pool while the connection pool still has capacity, or vice versa. Understanding which layer is the bottleneck requires measuring both.
Can increasing Max Pool Size in the connection string fix connection pool exhaustion?
Only temporarily, and only in cases where the exhaustion is caused by genuine high concurrency rather than leaks. If the root cause is a connection that is never returned to the pool (a leak), increasing the pool size just delays the next exhaustion. The correct fix is finding and eliminating the leak. Increase Max Pool Size only after you have confirmed the pool is legitimately being fully utilised by healthy, returning connections.
Is IDbContextFactory<T> safe to inject into Singleton services?
Yes. IDbContextFactory<T> is itself a singleton-safe service. Each call to CreateDbContextAsync() creates a new, independent DbContext instance that you own. You must dispose it after use - it is not managed by DI scope. For fire-and-forget or transactional operations inside singleton services, IDbContextFactory<T> is the recommended pattern.
What happens if I forget to dispose the IServiceScope in a BackgroundService?
The DbContext instances resolved from that scope will not be disposed, which means the underlying ADO.NET connections will not be returned to the pool. If the background service loops indefinitely and creates scopes without disposing them, this is equivalent to a connection leak that accumulates on every iteration. Use await using or using blocks that wrap the entire scope lifetime to guarantee disposal even on exception.
How do I detect connection leaks in production before they exhaust the pool?
Configure OpenTelemetry metrics with the EF Core and ADO.NET meter sources. Watch for the active connection count approaching Max Pool Size. Correlate spikes with specific endpoints or background jobs using distributed tracing. Set up an alert that fires when active connections exceed 80% of the pool maximum - this gives you a window to investigate before the next exhaustion event. Querying your database server's active session count (e.g., pg_stat_activity for PostgreSQL) and cross-referencing with your application's connection count is also a useful offline audit technique.
Does switching from AddDbContext to AddDbContextPool fix connection pool exhaustion?
Not by itself. AddDbContextPool pools DbContext instances (reducing object allocation overhead), but it does not change how or when the underlying database connections are opened and closed. A DbContext pool instance that leaks a connection will still exhaust the ADO.NET pool. AddDbContextPool is a performance optimisation, not a fix for lifetime mismanagement.
About the Author
Celin Daniel is Co-founder of Coding Droplets with 13+ years of hands-on experience building, shipping, and operating .NET and ASP.NET Core systems in production. The guidance here comes from real projects and production incidents, not theory.
- Website: codingdroplets.com
- GitHub: github.com/codingdroplets
- YouTube: youtube.com/@CodingDroplets

