The Saga Pattern in ASP.NET Core: Choreography vs. Orchestration — Enterprise Decision Guide
Distributed transactions are one of the hardest problems in enterprise microservices. When a business operation spans multiple services — an order placement that must reserve inventory, charge a payment, and notify a warehouse — the absence of a distributed transaction manager forces you to make explicit architectural choices. The Saga pattern is how modern .NET teams solve this. It replaces the two-phase commit with a sequence of local transactions, each followed by compensating actions on failure. What the pattern does not decide for you is how those local transactions are coordinated: through choreography, where services communicate directly via events, or through orchestration, where a central coordinator drives the workflow. That choice has lasting consequences for your team's operational posture and your system's failure surface.
💡 Want implementation-ready .NET source code you can adapt fast? Join Coding Droplets on Patreon. 👉 https://www.patreon.com/CodingDroplets
What the Saga Pattern Actually Solves
Before choosing an implementation style, it helps to be precise about the problem. A traditional database transaction gives you atomicity — either every operation succeeds or everything rolls back. Cross-service operations cannot share a database transaction without tightly coupling your services' data stores, which defeats the purpose of microservices.
The Saga pattern reframes the problem: instead of a single atomic transaction, you define a series of smaller local transactions. Each local transaction updates a single service's data store and publishes a message or event that triggers the next step. If a step fails, previously completed steps are undone using compensating transactions — inverse operations defined in advance.
The critical insight is that sagas offer eventual consistency, not strong consistency. Your business processes need to tolerate a window in which the system is partially updated. For most enterprise workflows — order processing, approval chains, onboarding flows, and subscription management — eventual consistency is perfectly acceptable. For workflows that require hard real-time consistency across multiple data stores, sagas alone are insufficient.
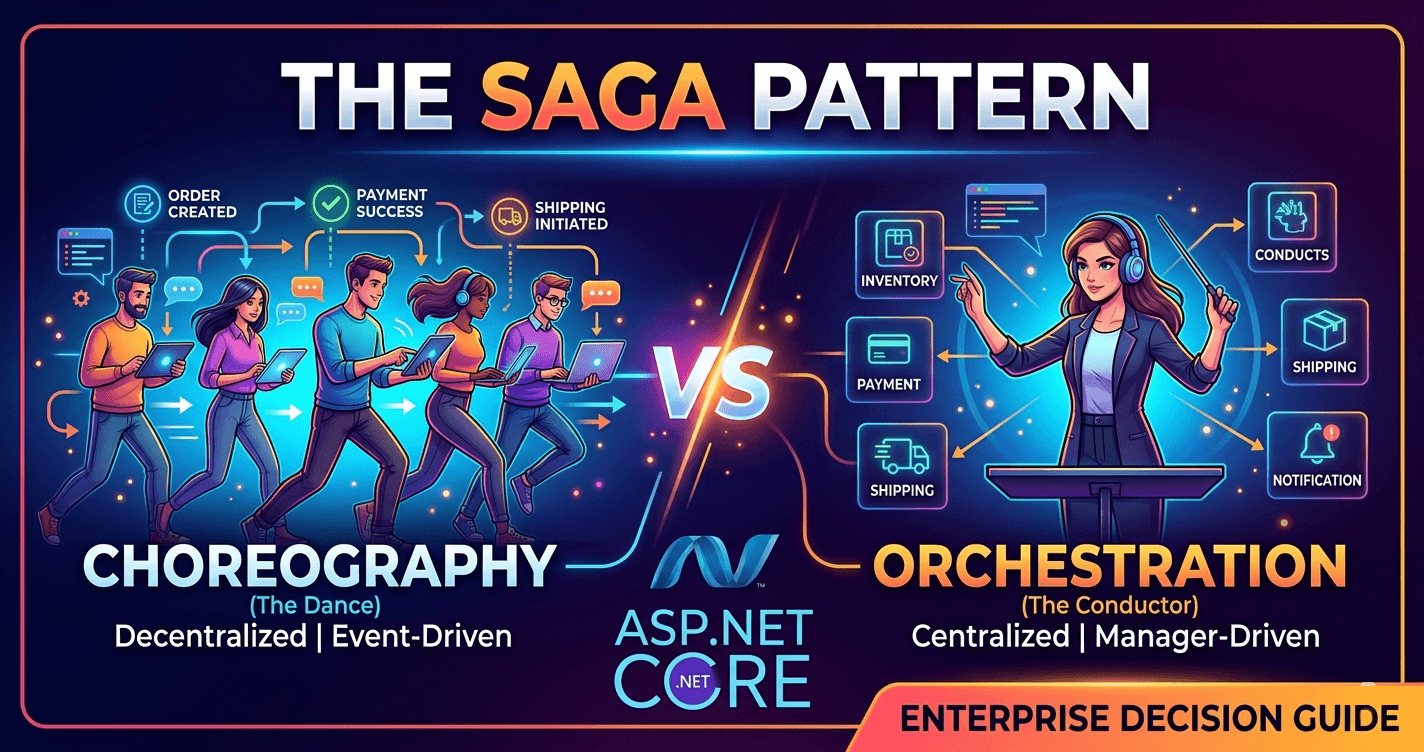
Choreography: Sagas Without a Conductor
In the choreography style, each service knows which events it publishes and which events it listens to. There is no central coordinator. When a service completes its local transaction, it emits a domain event. Other services consume that event and proceed with their own work.
The structural advantages of choreography are significant. Services remain genuinely decoupled: an order service does not need to know anything about the inventory service's internal implementation, only about the events they exchange. Adding a new service to a workflow means subscribing to the relevant events without touching existing services. For teams building towards independent deployability, choreography aligns naturally with those goals.
The operational risks surface at scale. As the number of participating services grows, the workflow becomes progressively harder to visualize. There is no single artifact that captures the full sequence of a business transaction. When a saga fails partway through, diagnosing the failure means correlating events across multiple service logs using a shared correlation identifier. Without disciplined distributed tracing — OpenTelemetry is almost mandatory here — debugging a stalled choreographed saga in production is genuinely painful.
When choreography fits enterprise teams:
Workflows with two to four steps where the sequence is stable
Teams with mature event-driven infrastructure and strong distributed tracing
Domains where services truly should not know about each other
Situations where adding new participants must not require touching existing services
When choreography becomes a liability:
Long-running workflows with six or more steps and complex branching
Teams that need clear visibility into the current state of a business transaction
Regulatory environments that require auditable workflow execution records
Any scenario where operators need to manually intervene in a stalled workflow
Orchestration: Sagas With a Conductor
In the orchestration style, a dedicated coordinator — the saga orchestrator — drives the workflow. It knows the sequence of steps, which services perform them, and what compensating transactions to trigger on failure. Participating services expose command handlers; the orchestrator tells them what to do and waits for responses.
Orchestration trades coupling for visibility. The orchestrator is a new component that introduces a dependency between coordinator and participants, but in return it becomes the single source of truth for workflow state. When something goes wrong, you query the orchestrator's state store. You get a snapshot of exactly which step failed, which compensating transactions have run, and what the current status is across all participants.
For enterprise teams operating under service-level agreements, orchestration dramatically reduces mean time to recovery. On-call engineers can look at a dashboard of orchestrator state rather than correlating events across six message broker topics.
Tooling in the .NET ecosystem reflects this trade-off. MassTransit's state machine sagas use a persistent state store (EF Core, Redis, or Azure Table Storage are common choices), making orchestration state observable and resumable after restarts. NServiceBus Sagas follow a similar pattern with its own persistence options including SQL Server and RavenDB. Both libraries handle the mechanics of message correlation, timeout management, and compensating transaction execution — which are non-trivial to build correctly from scratch.
When orchestration fits enterprise teams:
Multi-step workflows with branching logic, timeouts, and manual approval gates
Compliance-sensitive domains where every state transition needs an audit trail
Teams operating on-call rotations that need operational clarity at 3 AM
Workflows where business analysts need to understand current transaction status without reading code
When orchestration becomes a liability:
Simple two-step workflows where a coordinator adds unnecessary infrastructure
Highly decoupled domain areas where the orchestrator would create unwanted service knowledge
Teams who do not yet have persistence infrastructure configured for the orchestrator's state store
The Compensating Transaction Discipline
Regardless of which coordination style you choose, compensating transactions demand the same rigorous design discipline. Every forward step must have a defined inverse. These inverses are not automatic rollbacks — they are domain-level operations that explicitly reverse the semantic effect of a completed step.
Three categories of compensating transactions enterprise teams encounter:
Reversible operations can be fully undone. Reserving inventory can be unreserved. A pending authorization can be voided. These are straightforward to compensate.
Pivotal operations mark the point of no return. Once a payment is captured and a vendor notified, the operation is semantically complete even if subsequent steps fail. Compensation after a pivot means refund processes, vendor notifications, and customer communications — not a database rollback.
Retriable operations fail transiently and should be retried before triggering compensation. Network timeouts and temporary service unavailability belong here. Your saga implementation must distinguish retriable failures from permanent failures; libraries like Polly and MassTransit's built-in retry policies address this at the infrastructure level.
Idempotency: The Non-Negotiable Requirement
Both choreography and orchestration require every participant service to handle duplicate messages idempotently. Message brokers guarantee at-least-once delivery — messages will be delivered, but occasionally more than once. Without idempotency, compensating a saga might execute a refund twice. Reserving inventory twice is silently catastrophic.
The standard mechanism is an idempotency key — a unique identifier scoped to each saga step — checked against a processed-events store before executing any state-mutating logic. This store can be the same database as the service's primary data, checked within the same transaction as the business logic update. The Outbox Pattern, covered separately in Coding Droplets, addresses the dual-write problem that arises between local database commits and message publishing.
Timeout and Escalation Design
Enterprise sagas that involve external systems — payment gateways, third-party logistics providers, manual approval workflows — must account for timeouts explicitly. A saga waiting indefinitely for a response that never arrives is a resource leak and a user experience failure.
Design timeout policies at the saga level, not just at the HTTP call level. When the payment step has not completed within ninety seconds, the saga needs to make an active decision: retry, escalate to a human operator, or initiate compensation. MassTransit supports scheduled messages for timeout handling natively; NServiceBus provides saga timeouts as a first-class feature.
Escalation paths belong in your saga design diagrams before they belong in code. Identify every waiting step, define the maximum acceptable wait time, and document the escalation behavior. This exercise frequently surfaces missing product requirements.
Choosing Between MassTransit and NServiceBus for Enterprise Sagas
The .NET ecosystem has two mature frameworks for saga orchestration: MassTransit and NServiceBus.
MassTransit is open-source, free to use, and supports RabbitMQ, Azure Service Bus, Amazon SQS, and several other transports. Its saga state machine API has matured significantly through version 8 and beyond. It integrates with EF Core and Redis for state persistence and works naturally within ASP.NET Core's dependency injection model. For teams without an existing enterprise service bus investment, MassTransit is the pragmatic default choice.
NServiceBus from Particular Software carries a commercial license that scales with message volume. It is battle-tested in financial services, healthcare, and other regulated industries where support SLAs and long-term maintenance guarantees matter. Its saga support is older and arguably more opinionated, which reduces surface area for architectural mistakes. For teams in regulated environments where vendor support is a procurement requirement, NServiceBus justifies its cost.
The decision is rarely purely technical. Evaluate total cost of ownership including developer time for operational tooling, licensing, and infrastructure support contracts.
Observability Is Not Optional
A saga that fails silently is more dangerous than a saga that crashes loudly. Enterprise implementations must emit structured telemetry at every state transition: saga started, step completed, step failed, compensation triggered, saga completed, saga failed permanently.
OpenTelemetry spans, structured log entries with correlation identifiers, and metrics on saga duration and failure rates are the minimum viable observability posture. Both MassTransit and NServiceBus emit telemetry hooks that integrate with OpenTelemetry exporters. Your distributed tracing platform — whether Jaeger, Honeycomb, Azure Monitor, or Datadog — should be configured to capture the full saga trace as a single coherent operation.
On-call engineers cannot fix what they cannot observe. Define alerting thresholds on saga failure rates and saga duration percentiles before you deploy to production.
Decision Summary
Choreography is the right starting point for genuinely decoupled, low-complexity workflows where adding participants should not require touching existing services. It works best when your team has strong distributed tracing infrastructure and the domain naturally expresses itself as event streams.
Orchestration is the right choice for multi-step, long-running, branching workflows in compliance-sensitive or operationally complex environments. It trades some degree of coupling for dramatic improvements in observability, debuggability, and operational control.
Most enterprise systems need both. Use choreography for domain events that communicate facts across bounded contexts and orchestration for business processes that require explicit workflow management and state visibility.
Frequently Asked Questions
How is the Saga pattern different from using a distributed transaction manager? Distributed transaction managers like two-phase commit require a lock across all participating data stores for the duration of the transaction, which hurts availability and creates tight coupling. The Saga pattern uses a sequence of local transactions with compensating actions, achieving eventual consistency without cross-service locking. This makes sagas more resilient to partial failures and more compatible with independent service deployment.
Which coordination style should a team choose when starting with sagas for the first time? Orchestration is generally safer for first-time adopters. The explicit workflow state, visible in a persistent state store, makes it easier to debug and understand the system's behavior during development and early production operations. Teams can always introduce choreography for specific bounded contexts once they have more experience with saga failure modes.
Can sagas guarantee data consistency across services? Sagas guarantee eventual consistency, not strong consistency. There will be windows of time during which the system is in a partially updated state. Business processes need to be designed to tolerate this. For workflows where even a brief period of inconsistency is unacceptable — financial ledger operations, for example — sagas must be supplemented with additional consistency controls such as idempotency keys, optimistic concurrency, and carefully designed compensating transactions.
How do timeouts interact with compensating transactions in a saga? A timeout triggers a decision point, not automatic compensation. The saga orchestrator (or the choreographed participant) must decide whether to retry the timed-out step, escalate to a human operator, or initiate compensation. The appropriate action depends on the business context. Payment timeouts typically warrant a check-then-decide flow — confirming whether the payment was processed before triggering a refund — rather than immediately compensating.
Is the Outbox Pattern required when implementing sagas? The Outbox Pattern is strongly recommended for any saga participant that performs a local database write and then publishes a message. Without it, a crash between the database commit and the message publish leaves the saga in an inconsistent state — the local transaction succeeded but downstream services were never notified. The Outbox Pattern ensures that message publishing is atomic with respect to the local database transaction, which is a foundational reliability guarantee for any saga implementation.
How does saga state persistence work in MassTransit? MassTransit sagas persist state to a backing store — commonly EF Core with SQL Server or PostgreSQL, or Redis for lower-latency scenarios. Each saga instance is identified by a correlation ID that links it to the originating business event. On each message received, MassTransit loads the saga instance from the store, processes the message, updates the state, and saves it back. This persistence is what makes sagas resumable across service restarts and deployable on multiple instances without coordination issues.
What happens when a compensating transaction itself fails? Compensation failures are one of the hardest problems in saga design. The standard enterprise approach is to persist the failed compensation alongside the saga state, alert on-call engineers via automated monitoring, and design a manual or automated retry pathway. Some organizations implement a dead-letter saga state that feeds into a reconciliation workflow. There is no framework-level magic here — compensation failure handling is a business and operational design decision that must be made explicit before production deployment.