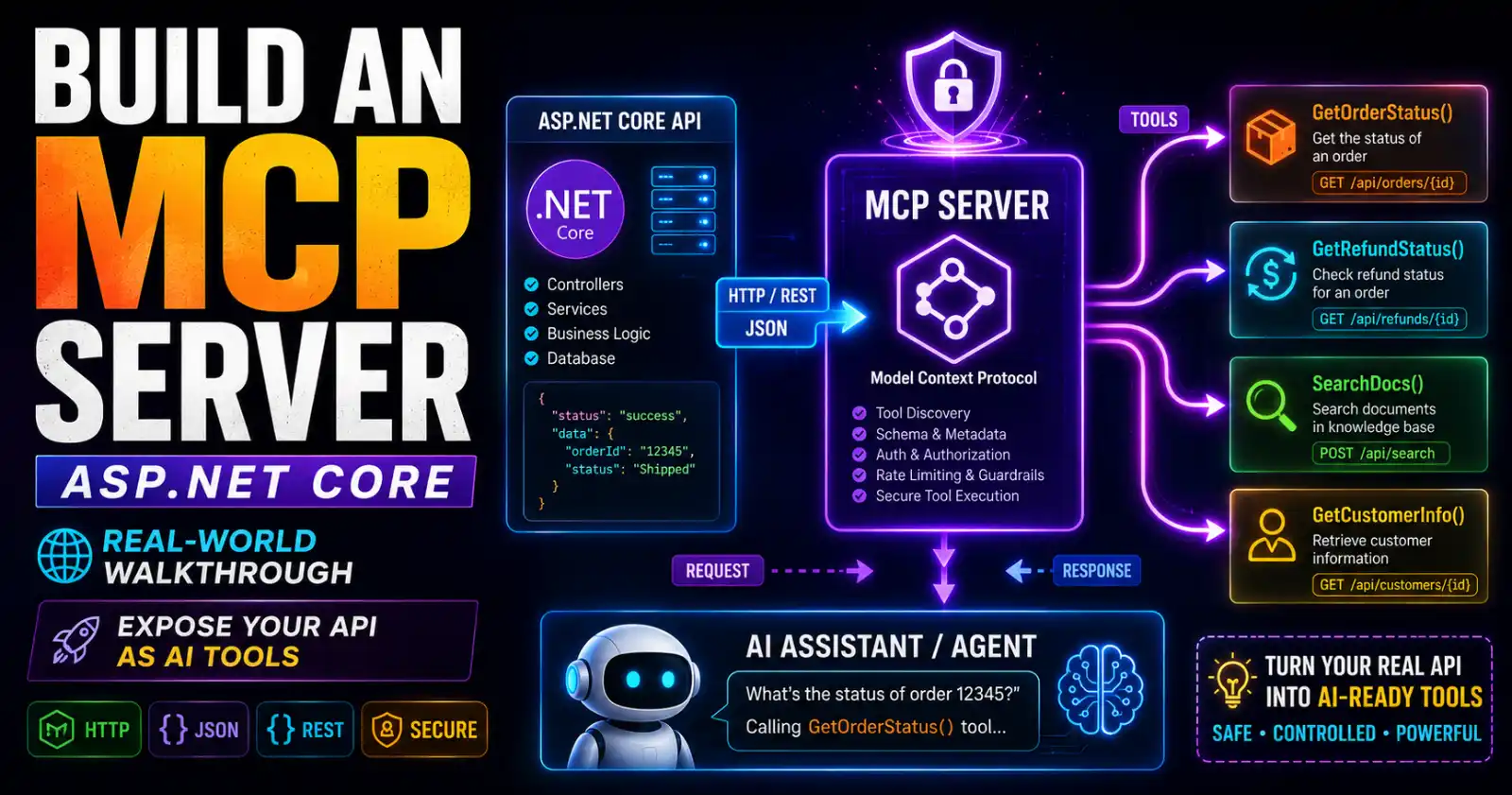
The 12-Point ASP.NET Core Production Readiness Checklist for .NET Teams

Shipping an ASP.NET Core API that works in development is the easy part. Shipping one that holds up under real-world traffic, survives restarts, handles secrets correctly, and tells you what's wrong at 2 AM — that's a different discipline. Most teams piece this together after their first painful incident. This checklist is a structured alternative to that.
The full production-ready implementation of these patterns — with working source code, edge cases handled, and everything wired together the way it would be in a real enterprise codebase — is available on Patreon. The patterns here will give you the framework; the complete picture lives there.
If you want to see how these production patterns fit into a complete API built from scratch, Chapters 14 and 15 of the ASP.NET Core Web API: Zero to Production course walk through structured logging, OpenTelemetry, health checks, and a full Dockerised deployment — with source code you can run immediately.

Use this checklist before every production release. Each item represents a category of risk that has caused real incidents in real .NET applications. Check every item, not just the ones your team considers "obvious."
1. Environment Configuration Is Correct
The most common source of silent production failures is configuration. The application runs fine locally because appsettings.Development.json fills in the gaps, but production doesn't have that fallback.
Before shipping, verify:
ASPNETCORE_ENVIRONMENTis explicitly set toProductionin the deployment target — never rely on defaults- All required environment variables are present and non-empty at startup
- No connection strings or API keys exist in
appsettings.jsonthat should only be in environment-specific overrides - The Options pattern (
IOptions<T>) withValidateDataAnnotations()andValidateOnStart()is used so misconfigured services fail immediately at startup rather than silently at runtime
The runtime should refuse to start with a bad configuration, not fail its first request.
2. Secrets Are Not in Source Control
Sensitive values — database passwords, JWT signing keys, API secrets — must never appear in appsettings.json or any file committed to source control. This is a non-negotiable.
The correct hierarchy for secrets management in .NET:
- Development: User Secrets (
dotnet user-secrets) — stored outside the repository, never committed - CI/CD: Pipeline secrets injected as environment variables at build or deploy time
- Production: A secrets manager — Azure Key Vault, AWS Secrets Manager, or HashiCorp Vault — accessed at startup via a configuration provider
If you are still seeing connection strings in your appsettings.json, this is the most important item on this checklist to fix.
3. Health Checks Are Configured and Wired to Your Infrastructure
A production API without health checks is invisible to the infrastructure that hosts it. Kubernetes, load balancers, and container orchestrators use health endpoints to decide whether to route traffic to an instance or restart it.
The three probe types serve different purposes:
- Liveness — Is the process alive? Failing this causes a container restart.
- Readiness — Is the API ready to serve traffic? Failing this removes the instance from the load balancer rotation without restarting it.
- Startup — Has the application finished initialising? Prevents liveness checks from killing slow-starting containers prematurely.
Each probe should have a distinct endpoint. Wiring all three to the same /health endpoint is one of the most common misconfiguration patterns — it causes restarts when the API is simply waiting for its database to become available.
For a detailed breakdown of how to configure all three correctly, see ASP.NET Core Health Checks: Liveness vs Readiness vs Startup Probes in .NET.
4. Structured Logging Is in Place and Configured Correctly
Console.WriteLine is not logging. A production API needs structured, queryable logs with consistent field names, log levels used correctly, and a sink that persists or ships them somewhere searchable.
Production logging checklist:
- Named placeholders are used, not string interpolation —
Log.Information("Order {OrderId} placed", orderId)not$"Order {orderId} placed" - Log levels are used correctly:
Warningfor recoverable problems,Errorfor failures requiring attention,Informationfor significant state changes - Request logging via
UseSerilogRequestLogging()(or equivalent) replaces the default per-request noise with one structured entry per request - Sensitive fields (passwords, tokens, PII) are not logged — even at
Debuglevel - The log sink (file, Seq, Application Insights, Grafana Loki) is configured for the production environment
For a detailed comparison of logging providers, see ASP.NET Core Structured Logging: Serilog vs NLog vs ILogger — Enterprise Decision Guide.
5. Global Exception Handling Is Configured
Unhandled exceptions should never reach the client as a raw stack trace. In .NET 8+, IExceptionHandler is the preferred mechanism for centralised exception handling. It maps typed exceptions to appropriate HTTP status codes and returns Problem Details (RFC 7807) compliant responses.
Before shipping:
UseExceptionHandler()is placed first in the middleware pipeline- Typed domain exceptions (
NotFoundException,ConflictException,ValidationException) map to the correct HTTP status codes (404, 409, 422) - 5xx responses never include
exception.Message— log the details server-side and return a generic message to the client - Problem Details responses include a
traceIdor correlation ID so a specific log entry can be located quickly
The goal is a system where the client gets a structured, actionable error response and you get a correlated log entry — never the reverse.
6. Authentication and Authorisation Are Production-Ready
Development shortcuts in auth configurations are a common source of production vulnerabilities. Before every release:
- JWT validation parameters are set correctly:
ClockSkew = TimeSpan.Zero, issuer and audience validation enabled, signing key loaded from secrets (not hardcoded) [Authorize]is the default for write endpoints — access should be explicitly granted, not accidentally left open- Refresh token rotation is implemented — old refresh tokens are invalidated on use
- Role and policy-based authorisation is applied to administrative endpoints — not just
[Authorize]
For a thorough security controls review, see ASP.NET Core API Security Checklist: 15 Production Controls Teams Miss.
7. Rate Limiting Is Enabled
Without rate limiting, a single misbehaving client or a simple script can exhaust your API's capacity. ASP.NET Core has built-in rate limiting middleware since .NET 7 — there is no longer any reason to rely on third-party solutions or skip this entirely.
Before shipping:
- A global rate limiter is configured as a baseline — prevents any single IP from flooding the API
- Authenticated endpoints partition by user identity, not just by IP
- The
OnRejectedhandler returns a429status with aRetry-Afterheader and a Problem Details body - Rate limiting policies are documented — your team should know what limits apply to which endpoints and why
8. Caching Strategy Is Appropriate for the Access Patterns
Caching misconfiguration is one of the subtler causes of production issues. Both over-caching (serving stale data silently) and under-caching (hammering the database on every request) cause real problems.
Before shipping, confirm:
IMemoryCacheis used for single-instance scenarios only — never as a distributed cache across multiple replicasIDistributedCachewith Redis is used for shared state across instances- Cache keys are deterministic and include all the variables that affect the response (user ID, page number, filters)
- Absolute and sliding expirations are set explicitly — relying on defaults leaves your cache filling up with entries that never expire
HybridCache(.NET 9+) is evaluated for read-heavy endpoints where both L1 (in-process) and L2 (Redis) cache layers reduce latency and prevent cache stampedes
9. Graceful Shutdown Is Wired Correctly
An API that can't shut down cleanly drops in-flight requests. In containerised deployments, this happens every time a pod is replaced — which means every deployment.
For graceful shutdown:
StopAsynccancellation token is respected in background services — tasks complete their current unit of work before stopping- The shutdown timeout is set explicitly and is long enough for in-flight requests to complete
SIGTERMis handled correctly — in Docker and Kubernetes, this is the signal sent beforeSIGKILL- Long-running background jobs (Hangfire, etc.) are configured with a graceful stop policy
For a full breakdown, see ASP.NET Core Graceful Shutdown: IHostApplicationLifetime vs Shutdown Timeout vs SIGTERM — Enterprise Decision Guide.
10. Database and EF Core Configuration Is Production-Safe
Several EF Core defaults are fine for development but cause problems at scale:
MigrateAsync()is called at startup (inside a retry loop) rather than leaving unapplied migrations as a silent time bombAsNoTracking()is used on all read-only queries — the change tracker adds overhead that is invisible in development but measurable under load- Connection resiliency (execution strategy with retry) is configured for transient failure scenarios, particularly on cloud databases
- Lazy loading is disabled — it triggers the N+1 query pattern silently and is one of the most common causes of unexpected query volume in production
11. The Docker Image Is Production-Grade
If you're deploying via containers:
- The final image uses the
runtimebase image, notsdk— the SDK image is 3-5x larger and exposes build tooling - A non-root user is declared and used in the Dockerfile — running as root inside a container is a security risk
.dockerignoreexcludesbin/,obj/, local secrets, and development-only files- Multi-stage builds are used — one stage for restore and build, one for the final runtime image
- The image tag strategy uses content-based tags (Git SHA or build ID) rather than
latest—latestmakes rollbacks unreliable
12. Observability Is Connected
An API is only truly production-ready when you can see what it's doing. Deploying without observability is flying blind.
Before shipping:
- OpenTelemetry is configured with traces, metrics, and logs exported to your chosen backend (Jaeger, Prometheus/Grafana, Application Insights, or an OTLP-compatible collector)
- The
/metricsendpoint (if using Prometheus) is secured — not publicly accessible - A dashboard exists for the key API metrics: request rate, error rate, p95/p99 latency, active connections
- Alerting is configured for: sustained 5xx error rate, p99 latency spike, and health check failures
Observability is not a nice-to-have. It is the mechanism by which you find out that something is wrong before your users do.
How to Use This Checklist
Run through all 12 items before every production deployment, not just the first one. Configuration drift is real — things that were correct at launch get quietly changed over time.
Consider converting this into a pull request template or a release gate in your CI/CD pipeline. The categories that bite teams most often are 1 (environment config), 2 (secrets), and 5 (exception handling) — start there if you're retrofitting an existing API.
☕ If this checklist saved you from an incident, buy us a coffee — it keeps the content coming!
FAQ
What is an ASP.NET Core production readiness checklist?
A production readiness checklist for ASP.NET Core is a structured list of configuration, security, resilience, and observability requirements that an API must meet before it is deployed to a live environment. It covers areas like health checks, secrets management, structured logging, graceful shutdown, and containerisation — the things that work differently in production than in development.
Why do ASP.NET Core APIs fail in production but not in development?
The most common causes are environment-specific configuration gaps (missing environment variables, wrong connection strings), missing health checks that prevent infrastructure from detecting unhealthy instances, unhandled exceptions that return raw stack traces, and auth shortcuts that were acceptable during development. A pre-deployment checklist makes these gaps visible before they cause an incident.
What health check endpoints should an ASP.NET Core API expose?
At minimum, a production ASP.NET Core API should expose three health check endpoints mapped to different purposes: a liveness endpoint (is the process alive?), a readiness endpoint (is it ready to serve traffic?), and optionally a startup endpoint (has initialisation completed?). Each endpoint should be wired to the correct Kubernetes probe type to avoid unnecessary restarts.
How should secrets be managed in a production ASP.NET Core API?
Production secrets should never be stored in source code or appsettings.json. The correct approach depends on the environment: use dotnet user-secrets for local development, pipeline-injected environment variables for CI/CD, and a secrets manager (Azure Key Vault, AWS Secrets Manager, or HashiCorp Vault) for production deployments. The .NET configuration provider model supports all of these with consistent access patterns via IOptions<T>.
What is the difference between liveness and readiness probes in ASP.NET Core?
A liveness probe tells the infrastructure whether the process is alive and should be restarted if it fails. A readiness probe tells the infrastructure whether the instance is ready to receive traffic — it can fail without triggering a restart, which is appropriate when the API is waiting for a downstream dependency. Confusing the two is one of the most common causes of unnecessary restarts during deployments.
When should you use IMemoryCache vs IDistributedCache in production?
IMemoryCache stores data in the process's memory and is only appropriate for single-instance deployments or data that can be stale per-instance. When running multiple replicas (which is standard in production), IDistributedCache with Redis is required so all instances share the same cache state. Using IMemoryCache in a multi-instance deployment causes cache inconsistency that is very difficult to debug.
What does graceful shutdown mean for an ASP.NET Core API in Kubernetes?
Graceful shutdown means that when Kubernetes sends a SIGTERM signal to a pod, the application finishes processing in-flight requests, stops accepting new ones, and only then exits — rather than terminating immediately and dropping requests mid-way. In ASP.NET Core, this requires respecting CancellationToken in background services, setting an appropriate shutdown timeout, and ensuring Hangfire or other job runners have a clean stop path.
Is rate limiting required for internal APIs?
Yes. Even internal APIs can be overwhelmed by a misbehaving service, a bug in a consumer, or an unexpected burst of traffic during a deployment. Rate limiting protects the API from any source of excessive load, not just external attackers. ASP.NET Core's built-in rate limiting middleware is lightweight and should be enabled for all APIs, with appropriate limits tuned to actual traffic patterns.