EF Core Data Seeding in ASP.NET Core: HasData vs UseSeeding vs Custom Seeder Service — Enterprise Decision Guide
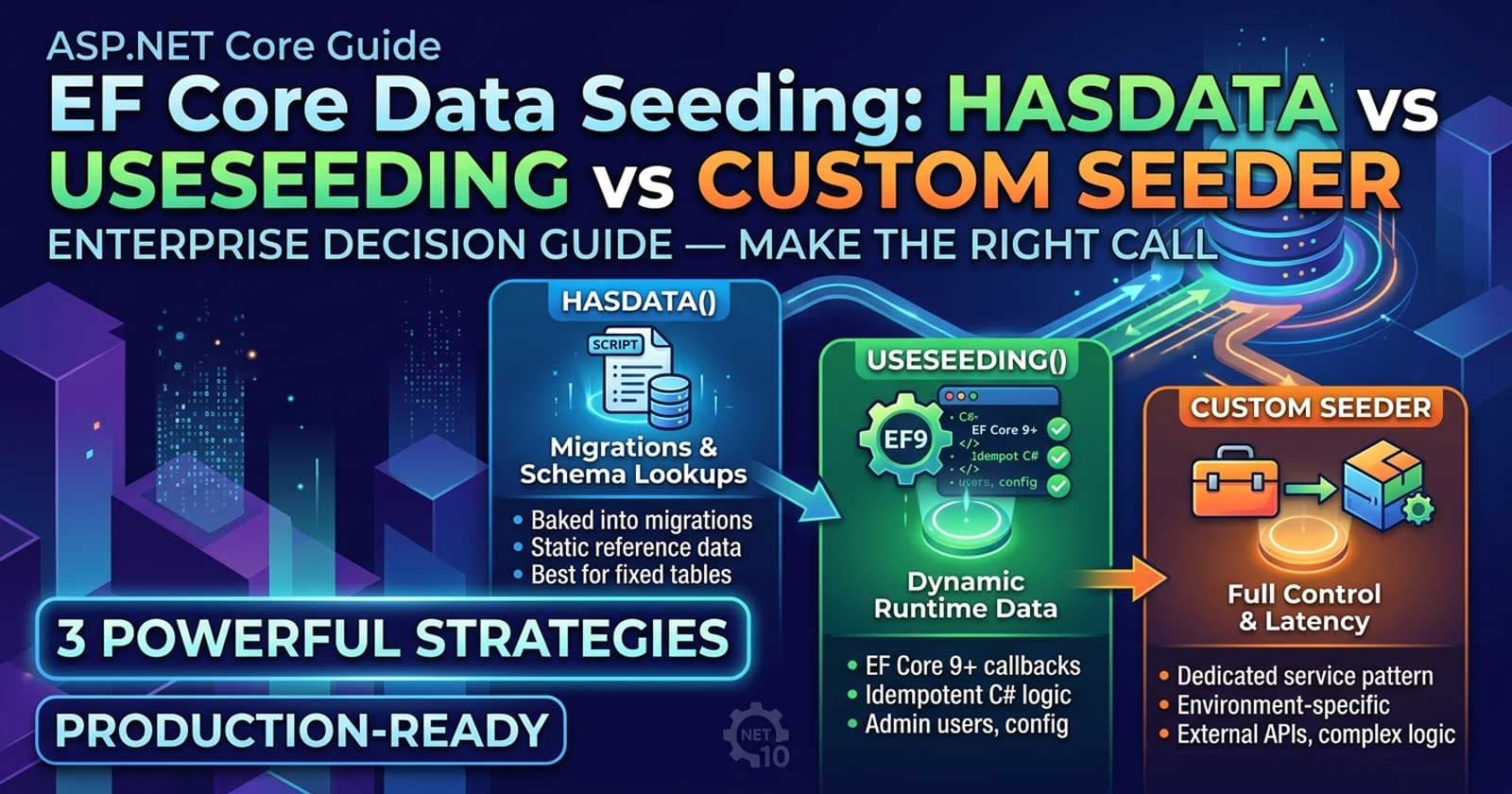
Every production API eventually faces the same set of questions: how do you get the initial data into the database? When does seeding belong in a migration? When should it run at startup? And when does a custom seeder service make more sense than either? The three EF Core data seeding strategies — HasData, UseSeeding/UseAsyncSeeding, and a custom IDataSeeder service pattern — each serve a distinct purpose, and choosing the wrong one creates problems that compound over time.
If you want to see all three strategies running side by side in a real project, the full production-ready implementation is on Patreon — including idempotency patterns, environment-specific seeding, and a complete test suite that validates each approach.
Understanding why these three mechanisms exist requires first understanding what EF Core changed in version 9. The HasData method, which many teams still use as a general-purpose seeder, was deliberately renamed to "model managed data" in the official documentation. The naming shift signals something important: HasData was never designed to be a general seeding mechanism. It exists for data that is structurally part of your schema, not data that changes, grows, or depends on runtime conditions. The UseSeeding and UseAsyncSeeding methods, introduced in EF Core 9 and available in EF Core 10, were added specifically because the community was using HasData for things it was never designed to support. Chapter 3 of the ASP.NET Core Web API: Zero to Production course walks through EF Core entity design, migrations, and HasData seeding inside a full production codebase — if you want to see these patterns wired together with domain entities and a real DbContext, that is the place to start.
What Each Strategy Actually Does
Before reaching for any of these tools, it is worth understanding what each one actually does under the hood — because the execution model determines the failure modes.
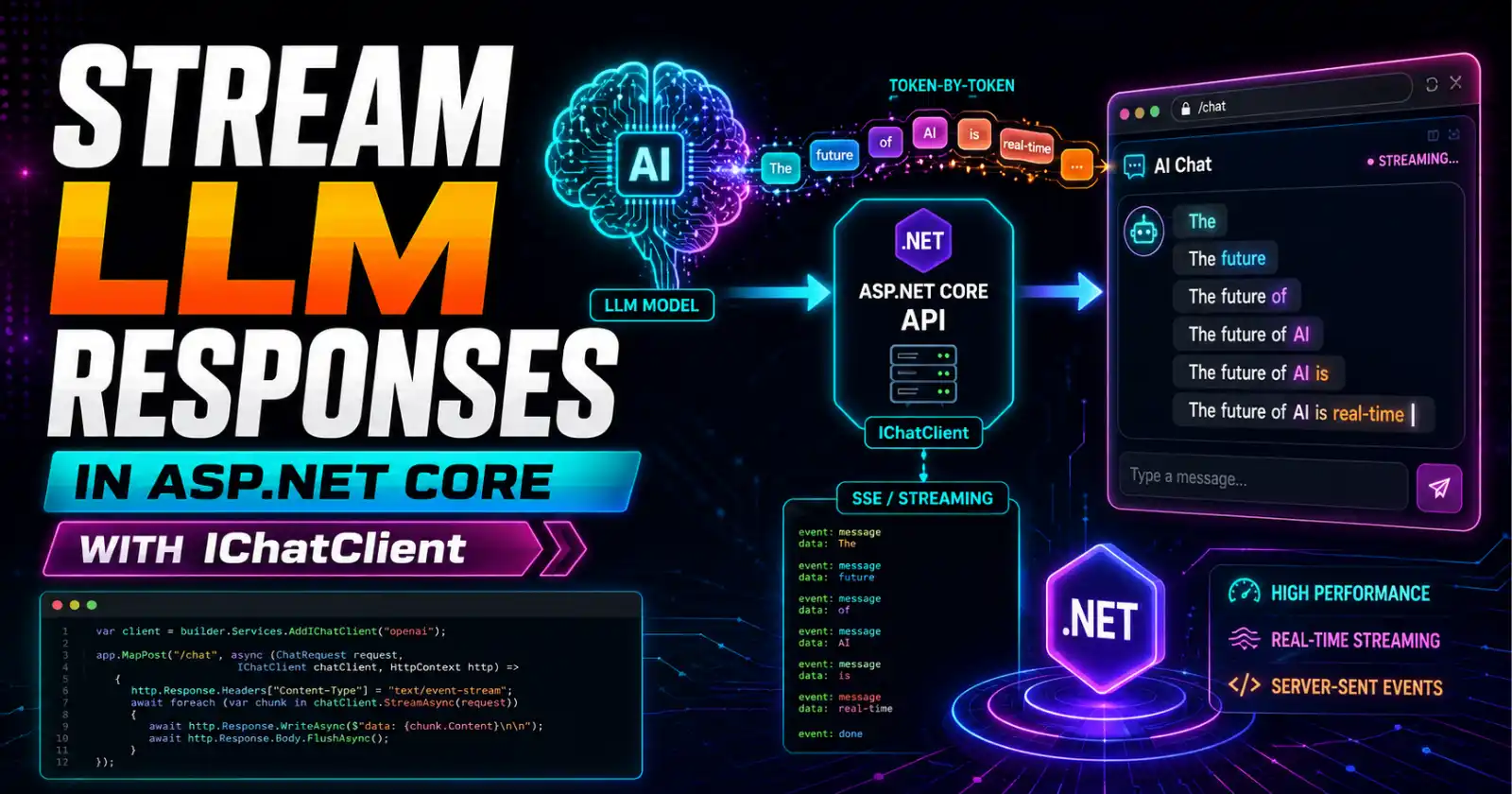
HasData bakes seed data directly into your EF Core migrations. When you call HasData() inside OnModelCreating, EF Core generates SQL INSERT statements in a migration file the next time you run dotnet ef migrations add. Those statements are versioned alongside your schema. The data becomes part of the migration history. If you change a value in HasData, EF generates a new migration with an UPDATE or DELETE — and that migration runs in every environment, every deployment, whether the data changed in that environment or not.
UseSeeding and UseAsyncSeeding are callbacks registered on DbContext that run after Database.EnsureCreated() or Database.MigrateAsync() completes. The code inside these callbacks runs at application startup or migration execution time, but it does not generate migration SQL. It is plain C# with full access to the DbContext, which means it can check whether data already exists, hash passwords, call external services, or apply logic that would be impossible to express in a static migration.
A custom IDataSeeder service is not a built-in EF Core feature — it is an architectural pattern where seeding logic is extracted into a dedicated service, typically an IHostedService or a service called from Program.cs startup. This pattern gives you the most control: you decide exactly when seeding runs, what conditions trigger it, and how failures are handled. The trade-off is that you own the orchestration entirely.
When to Use HasData
HasData is the right choice when the data is structurally equivalent to a lookup table — data that defines the fixed vocabulary of your domain. Think permission types, status enums stored in database tables, ISO country codes, currency codes, or base system roles.
The decision signal is this: if the data changing in production would require a schema migration anyway, it belongs in HasData. If a new country ISO code or a new permission type changes the valid set of values your application can reference, that is a schema-level concern — and HasData encodes it correctly.
The failure mode to watch for is teams using HasData for data that should grow independently of deployments: admin user accounts, default tenant configurations, or application settings. These will generate spurious migrations any time someone updates a value in development, and those migrations can conflict with production data that has evolved independently.
HasData also requires that every record has a primary key value explicitly specified. This is necessary because EF needs to track which rows to update or delete in later migrations. The moment your seed data involves generated keys or depends on other rows being inserted first, HasData becomes awkward and error-prone.
When to Use UseSeeding and UseAsyncSeeding
UseSeeding is the right choice for seed data that is dynamic, conditional, or environment-specific. The quintessential example is an initial admin account with a hashed password — you cannot put password hashing logic inside a migration SQL statement. Another common case is seeding default configuration rows where the values differ between development, staging, and production.
The execution contract with UseSeeding is that it runs every time Database.MigrateAsync() completes. This means the code inside it must be idempotent — it needs to check whether data already exists before inserting it. A seeder that inserts without checking will produce duplicate rows or primary key violations on every subsequent startup.
The recommended pattern is to check for the presence of a sentinel record before inserting the full dataset. For small reference sets, a simple count check is sufficient. For larger datasets, checking for the most recently added record and comparing against a version identifier works well.
UseSeeding also solves the problem of seeding order. Because it runs after all migrations have applied, foreign key constraints are already in place, and you can rely on the schema being in its expected final state. This makes it safe to seed data that has relationships — something HasData handles awkwardly due to migration ordering constraints.
When to Use a Custom Seeder Service
A custom seeder service pattern is warranted when seeding logic needs to be invoked on a schedule, triggered by an external condition, or tested in isolation. It is also the right approach when seeding involves significant latency — calls to an external identity provider, bulk data imports from a file, or setting up tenant databases in a multi-tenant system.
The typical implementation registers a service that implements IHostedService or is invoked explicitly during application startup after the DI container is built. The service resolves a scoped DbContext using IServiceScopeFactory — the same pattern required whenever a long-lived service needs to interact with scoped services.
This pattern also enables per-environment seeding configurations. A DevelopmentSeeder class can register thousands of rows of test data. A ProductionSeeder can limit itself to critical reference data and admin bootstrap records. The seeder registration in Program.cs switches based on IHostEnvironment.IsDevelopment(). This separation is cleaner than embedding environment checks inside UseSeeding callbacks, which tend to accumulate conditionals over time.
The cost of this pattern is ownership of the orchestration layer. You need to decide what happens when seeding fails, whether to retry, whether to block application startup until seeding completes, and how to signal readiness to Kubernetes health checks. These are all solvable problems — but they require explicit decisions that the built-in EF Core approaches handle implicitly.
Is There a Right Default for .NET Teams?
For most ASP.NET Core projects starting in 2026, the right default is a two-layer approach: HasData for static reference data that belongs to the schema, and a custom seeder service for everything else.
UseSeeding works well for smaller projects where the seeding logic is simple and bounded. It starts to break down when different seeding scenarios have different operational requirements — test data that should never run in production, bootstrap logic that needs retry handling, or seeding that must interact with non-database services.
The combination of HasData for schema-level lookups and a custom seeder service for runtime initialization keeps the migration history clean, keeps the startup logic explicit, and makes the seeding logic independently testable.
The Anti-Patterns That Create Problems in Production
The most common mistake is using HasData for admin accounts or application settings. The moment that data needs to change in a running system without a deployment, the approach breaks. Admin users change their passwords. Settings drift between environments. HasData generates a migration that reasserts the original values, which can overwrite or conflict with changes made in production.
The second common mistake is non-idempotent UseSeeding logic — inserting data without first checking whether it already exists. This produces primary key violations or duplicate rows on every startup after the first. The check-before-insert pattern is mandatory, not optional.
The third mistake is seeding during migrations in a CI/CD pipeline context. If your seeder runs inside Database.MigrateAsync() and produces an error, the entire migration call fails — and the deployment pipeline sees a failed startup, not a failed seed. For production systems, seeding that can fail independently should run after migrations complete, not inside them.
Decision Matrix
| Scenario | Recommended Approach |
|---|---|
| Static lookup tables (countries, currencies, permission types) | HasData |
| Initial admin account with hashed password | UseSeeding or custom seeder |
| Default configuration rows, environment-specific | Custom seeder service |
| Large test datasets for development | Custom seeder service |
| Data with relationships and FK constraints | UseSeeding or custom seeder |
| Seeding that must not run in production | Custom seeder service |
| Seeding that needs retry/failure handling | Custom seeder service |
| Simple, idempotent startup data | UseSeeding |
For teams using Clean Architecture or CQRS with MediatR, the custom seeder service fits naturally in the Application or Infrastructure layer, with interface definitions in Application and implementations in Infrastructure. This also makes the seeder independently testable without invoking the full startup pipeline. If you are thinking about where this fits in a larger EF Core production story, the EF Core Connection Resiliency Enterprise Decision Guide covers the complementary concern of making database access fault-tolerant in cloud environments. For teams working with the Specification Pattern, seeder services integrate cleanly as a first-class consumer of your repository interfaces — see The Specification Pattern in ASP.NET Core for how to structure that.
💻 Full source code available on GitHub — production-ready EF Core seeding patterns you can clone and adapt: github.com/codingdroplets/efcore-data-seeding-seeddata
☕ Prefer a one-time tip? Buy us a coffee — every bit helps keep the content coming!
What Does Changing HasData in Production Actually Do?
When you modify a value in HasData in your code, EF Core generates a new migration with an UPDATE statement. That migration runs against every environment — development, staging, and production — on the next deployment. If the value in production has drifted from what the migration expects, the update may silently overwrite it, or the migration may fail if it depends on a state that no longer matches. This is why HasData must be treated as append-only for data that can change after initial deployment.
External Authority Links
For full reference on EF Core seeding mechanics, the official documentation is authoritative: EF Core Data Seeding — Microsoft Learn. For the UseSeeding API specifically, the EF Core 9 release notes document the new methods and their execution contracts.
Frequently Asked Questions
Can I combine HasData and UseSeeding in the same project?
Yes, and in many projects this is the recommended approach. HasData handles static schema-level reference data — lookup tables, permission types, ISO codes. UseSeeding handles dynamic runtime data — admin accounts, default tenant configurations, anything that needs logic. The two mechanisms do not conflict; they serve different purposes and run in different contexts.
Does UseSeeding run on every application startup?UseSeeding runs every time Database.EnsureCreated() or Database.MigrateAsync() is called. In most production setups, migrations are applied as part of deployment, so UseSeeding runs once per deployment, not once per HTTP request. If you call MigrateAsync() at startup in a Kubernetes pod, it will run on every pod restart. This is why idempotency is mandatory — your seeder must check whether the data already exists before inserting it.
What happens if UseSeeding throws an exception?
If UseSeeding throws, the exception propagates out of MigrateAsync(), which typically causes the application to fail to start. This is a deployment failure, not a runtime error. For seeding that can fail independently — external API calls, large bulk operations — the custom seeder service pattern is better because you have full control over error handling and can choose to log and continue rather than failing the startup.
Should HasData run in production at all?HasData SQL runs as part of EF Core migrations, which run in every environment including production. The data defined in HasData is applied during deployment, not at runtime. This means it is safe for truly static data — but it also means any change to that data creates a migration that runs in production on the next deployment. Teams that have accidentally put mutable data in HasData often discover this the hard way when a migration overwrites production values.
Is UseSeeding the right place to create an initial admin user?
It is a reasonable choice for smaller projects. The logic goes inside UseAsyncSeeding, you check whether the admin account already exists, and you hash the password using BCrypt before inserting. The main limitation is that this runs inside the MigrateAsync() call, so a failure fails the migration. For production systems where admin bootstrapping is a one-time operation and failures should not block deployment, a custom seeder service with an idempotency check is more robust.
How do I prevent development-only seed data from running in production?
With the custom seeder service pattern, you register different implementations based on IHostEnvironment.IsDevelopment() in Program.cs. Development registers both the base seeder and a DevelopmentDataSeeder that adds test data. Production registers only the base seeder. With UseSeeding, you use app.Environment.IsDevelopment() as a guard inside the callback — this works but tends to accumulate conditionals as the project grows. The custom seeder service approach is cleaner at scale.
What is the difference between UseSeeding and UseAsyncSeeding?
Both are callbacks registered on DbContext that execute after EnsureCreated or Database.Migrate. UseSeeding is the synchronous version; UseAsyncSeeding is the async version. Microsoft's guidance is to implement both, because EF Core's synchronous and asynchronous code paths call them independently. In practice, ASP.NET Core applications almost always use the async path (MigrateAsync()), so UseAsyncSeeding is the one that runs at startup. Implementing UseSeeding as well ensures compatibility with tools or test setups that invoke the synchronous API.